- TheSoulsRemain
-
Vintage Méga utilisateur

- #1
- Publié par
TheSoulsRemain le 24 Mar 2025, 10:10
Sommaire :
Microphone : Niveaux et histoire :
https://www.guitariste.com/for(...)03143
Microphone : Sensibilité
https://www.guitariste.com/for(...)03144
Microphone : Niveau et Gain
https://www.guitariste.com/for(...)03144
Microphone : Structure de Gain
https://www.guitariste.com/for(...)03146
Microphone : Hertz et dBs
https://www.guitariste.com/for(...)03147
Microphone : SPL et Distortion
https://www.guitariste.com/for(...)03148
Ce qui suit est la traduction/adaptation d'une série d'article écrit par Greg Simmons.
J'ai utilisé ChatGPT à 99% pour la traduction. J'ai volontairement laissé des anglicismes et des acronymes parce que dans l'audio il y a des anglicismes partout et que certains mots ont des sens différents suivant le contexte. Par exemple clipping c'est une saturation mais un clipping numérique c'est aussi un "rabot"
https://www.audiotechnology.com/tutorials/microphones-tutorials/microphones-levels-history
Microphones : Niveaux et Histoire
Dans ce neuvième volet de cette série, nous examinons les nombreuses façons dont nous pouvons mesurer les niveaux de signal et comment cela peut nous aider à choisir des microphones et à régler le gain.
Par Greg Simmons
9 décembre 2021
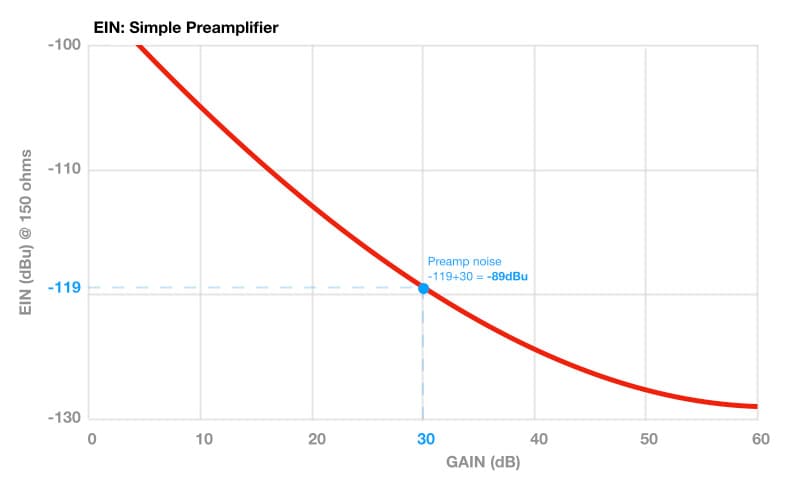
Dans les précédents volets, nous avons étudié plusieurs spécifications des microphones et des préamplificateurs liées aux niveaux de signal, toujours dans le but de minimiser le bruit et de réduire la possibilité de clipping dans nos signaux. L'objectif était d'associer la Sensibilité du microphone avec le SPL de la source sonore, afin que le contrôle de gain du préamplificateur n'ait pas besoin d'être trop élevé, ce qui rendrait le bruit plus apparent, mais qu'il ne soit pas non plus trop bas, ce qui indiquerait que la Sensibilité du microphone était trop élevée pour l'application et pourrait surcharger le chemin du signal et créer de la distorsion.
![]()
Avant de poursuivre, tu voudras peut-être revoir les quatre premiers volets de cette série pour rafraîchir ta mémoire sur la Sensibilité, le Bruit, le SPL et la Distorsion. Dans l'édition sur la Sensibilité, nous avons introduit le concept de la "Zone de Goldilocks" autour du contrôle de gain du préampli — une zone idéale où il faut garder le contrôle de gain. Dans l'édition sur le Bruit, nous avons étudié les sources de bruit dans le microphone et dans le préamplificateur (Bruit Brownien et Bruit Thermique) et ce que nous pouvons faire pour minimiser le bruit dans le signal capté et amplifié. Dans l'édition sur le SPL et la Distorsion, nous avons abordé la distorsion par clipping et les spécifications liées du microphone, telles que le SPL maximal et la plage dynamique. Toutes les spécifications abordées jusqu'à présent sont liées au niveau du signal.
Il est maintenant temps de tout rassembler et de voir comment ces éléments peuvent nous aider à choisir un microphone qui délivre un signal restant dans la Zone de Goldilocks du préamplificateur, ce qui entraînera moins de bruit et (espérons-le) pas de distorsion audible. Mais avant cela, nous devons comprendre certains concepts de base sur les signaux. Il y a beaucoup de choses à traiter ici ; si tu es impatient, peu curieux ou que tu crois encore que tu peux devenir ingénieur du son simplement en mémorisant des réglages vus sur Youtube, tu pourrais vouloir passer à l'édition suivante et revenir sur celle-ci plus tard pour mieux comprendre les raisons et le contexte historique.
LES FONDAMENTAUX DU SIGNAL ANALOGIQUE
Pour comprendre les spécifications des microphones et des préamplificateurs liées aux niveaux de signal, nous devons comprendre certains principes généraux des niveaux de signal analogiques, et la meilleure manière de le faire est de commencer par leurs limitations.
Comme nous l'avons appris dans les précédentes éditions, tout ce que le son traverse a des limites qui déterminent jusqu’où le niveau du signal peut aller, aussi bien dans les niveaux bas que dans les niveaux hauts.
![]()
Bruit
Le niveau le plus bas que le signal peut atteindre est déterminé par le bruit — qu’il s’agisse du bruit acoustique dans l’espace que le son traverse, du bruit brownien dans les diaphragmes de microphone, du bruit thermique dans les électroniques audio analogiques, ou du bruit de quantification dans les systèmes numériques. Le niveau du bruit détermine en fin de compte le niveau sonore le plus faible qui peut être entendu et/ou le niveau de signal le plus bas qui peut être capté ; à mesure que le niveau sonore ou le niveau du signal tombe trop loin vers le bruit, il devient inintelligible et finalement inaudible.
Paradoxalement, dans les systèmes audio numériques, nous ajoutons du bruit pour permettre au signal de rester intelligible et audible à faibles niveaux. Ce bruit s'appelle le dither (ou "hachage"), et le processus consistant à l'ajouter s'appelle dithering. Appliquer du dither à un signal numérique transforme la rugosité du bruit de quantification en un souffle beaucoup plus acceptable — il est généralement plus fort que le bruit de quantification, mais beaucoup moins intrusif. Il est également utilisé dans l’imagerie numérique pour améliorer la perception visuelle des images en basse résolution, mais le dither est un sujet pour une autre fois.
Distorsion
Le niveau le plus élevé que le signal peut atteindre est déterminé par le point où la forme d'onde du son ou du signal est altérée en raison d'une forme de distorsion connue sous le nom de clipping, où les crêtes de la forme d'onde sont aplaties comme si elles avaient été coupées avec des ciseaux — comme cela a été discuté dans l'édition précédente. Le clipping se produit dans les circuits audio analogiques (y compris ceux trouvés à l’intérieur des microphones à condensateur et des microphones actifs) lorsque le niveau de tension de crête du signal tente de dépasser la tension maximale utilisée pour alimenter le circuit. Il se produit dans les systèmes numériques lorsque la valeur numérique de crête du signal tente de dépasser 0dBFS, qui est le plus grand nombre que le système numérique peut représenter. Le clipping se produit également dans l’air lorsque le son dépasse 194 dB SPL, moment où la demi-cycle négatif de la forme d’onde raréfie les molécules d’air pour créer un vide complet — ce qui est la pression atmosphérique négative la plus élevée possible. [Cette forme de clipping est un problème pour ceux qui enregistrent des feux d'artifice, des lancements de fusées, des explosions et des orages, car le son est déjà "clippé" par l'air avant d'atteindre le microphone, et aucune modification de gain, de commutation de pad ou de changement de microphone ne pourra y remédier. Il est intéressant de noter que, parce qu’il est uniquement "clippé" lors des demi-cycles négatifs, il s’agit d’une forme asymétrique de clipping, ce qui introduit un équilibre différent des composants de distorsion harmonique par rapport au clipping symétrique et peut parfois sembler moins intrusif et, dans certains cas, plus musical — comme on peut l’entendre dans les amplificateurs de guitare électrique.] Dans tous les cas, si le niveau du signal dépasse trop loin dans le clipping, nous avons un problème.
Puisque notre objectif dans cette édition est de traiter des niveaux de signal, nous allons examiner comment les limitations du clipping et du bruit se manifestent dans les circuits audio tels que les préamplificateurs de microphones et les systèmes audio numériques, et comment cela influence nos choix de microphones. Mais d’abord, un rapide aperçu des trois types de niveaux de signal que nous rencontrons régulièrement dans l’ingénierie audio : Niveau Microphone, Niveau Ligne et Niveau Instrument.
![]()
Niveau Microphone (Mic Level)
À moins que nous n’utilisions un microphone avec une sortie numérique (par exemple, AES42, USB ou MEMS), le signal présenté à la sortie de notre microphone est une très petite tension analogique, généralement mesurée en centièmes ou millièmes de volt. Lorsqu'il est converti en décibels, il se situe généralement entre -60dBu (0,000775 VRMS) et -20dBu (0,0775 VRMS). Ce signal est appelé Niveau Microphone, et il doit passer par un préamplificateur pour être porté à un niveau utile pour le traitement et/ou l’enregistrement (c'est-à-dire, Niveau Ligne).
Les signaux de Niveau Microphone utilisent des lignes équilibrées et des connecteurs XLR. Les patchbays dans certains studios d'enregistrement professionnels permettent de faire passer les lignes de microphone vers les entrées des préamplificateurs via des câbles Bantam TT symétriques et des prises, bien que la connexion des microphones se fasse de préférence avec des prises et des fiches XLR. La plupart des fabricants de connecteurs XLR conçoivent la broche 1 légèrement plus longue que les broches 2 et 3 sur leurs connecteurs XLR femelles (généralement utilisés comme entrées) afin de garantir que la broche 1 (terre) se connecte en premier, une fonctionnalité de sécurité utile. Le fabricant de microphones Røde fait exprès de rendre la broche 1 légèrement plus longue sur leurs sorties XLR de microphones (qui sont des XLR mâles) pour la même raison — une excellente idée qui malheureusement amène les personnes mal informées à penser qu’il s’agit d’un défaut de fabrication, car une broche est plus longue que les autres.
[Pour éviter les bruits de choc qui pourraient endommager les haut-parleurs de monitoring, les casques et l’audition, il est toujours conseillé de couper le monitoring lorsque vous patcher des microphones — surtout si vous utilisez l'alimentation fantôme, et encore plus si vous utilisez des connecteurs Bantam TT (plutôt que des XLR) parce que leur configuration anneau/pointe/manchon signifie que, pendant un court moment, vous pourriez fournir un signal d’entrée de +48V DC au microphone. Cela suffit à endommager les haut-parleurs passifs, les casques, l’audition humaine, et toute crédibilité que vous avez pu établir avec le client.]
Niveau Ligne (Line Level)
Le rôle du préamplificateur de microphone est d'amplifier le signal de Niveau Microphone à un niveau utile pour un traitement ultérieur, qui est généralement appelé Niveau Ligne.
La plupart des signaux de Niveau Ligne utilisent des lignes équilibrées avec des connecteurs XLR, des prises TRS ou les connexions Bantam TT que l'on retrouve dans les patchbays des studios d’enregistrement professionnels. Nous parlerons davantage des signaux de Niveau Ligne sous peu, car l’objectif final du préamplificateur est de porter le signal de Niveau Microphone à Niveau Ligne…
Niveau Instrument (Instrument Level)
Les guitares électriques, les claviers et autres instruments musicaux électroniques conçus pour les performances en direct fournissent leurs sorties sur des prises TS 6,35 mm (une pour mono, deux pour stéréo), destinées à être connectées à un amplificateur d'instrument. Les signaux qu'ils produisent sont souvent appelés Niveau Instrument ; ils sont plus élevés que le Niveau Microphone mais plus faibles que le Niveau Ligne, se situant généralement autour de -20dBu (0,0775 VRMS). Ces signaux sont trop faibles pour la plupart des entrées de Niveau Ligne mais trop forts pour les entrées de Niveau Microphone, et ils sont généralement asymétriques, ce qui signifie qu'ils conviennent pour les câbles courts entre l’instrument et son amplificateur, mais pas pour des câbles longs entre la scène et la table de mixage dans une application de sonorisation. Ils sont généralement connectés à une console de mixage ou à un préamplificateur de microphone via une boîte DI, qui réduit le signal relativement élevé mais asymétrique du Niveau Instrument à un signal de Niveau Microphone relativement faible avec une sortie symétrique, adaptée pour les longues distances et pour entrer dans un préamplificateur de microphone.
Le rôle du préamplificateur de microphone est d'amplifier le signal de Niveau Microphone à un niveau utile pour un traitement ultérieur, généralement appelé Niveau Ligne.
![]()
Certains claviers et modules montés en rack fournissent une sortie de Niveau Ligne symétrique sur une prise XLR ou Jack TRS, et cela devrait être utilisé chaque fois que possible pour se connecter à une entrée de Niveau Ligne.
Lorsque vous travaillez avec des signaux de Niveau Instrument dans des situations où l'instrument est proche du préamplificateur ou de la console de mixage, il est souvent nécessaire de jongler entre le niveau de sortie de l'instrument et le gain du préamplificateur pour trouver la connexion la plus silencieuse tout en évitant le clipping. Bien que l’utilisation d’une boîte DI sur une entrée de Niveau Microphone soit courante, dans certains cas, une meilleure qualité de signal peut être obtenue en branchant directement la sortie de l’instrument sur une entrée de Niveau Ligne avec un contrôle de Trim ou Gain ajustable.
Certaines interfaces, surtout celles conçues pour les musiciens s’enregistrant, disposent d'une entrée de Niveau Instrument avec une prise Jack TS 6,35 mm, spécialement conçue pour accepter les signaux de Niveau Instrument. Ce devrait être le premier choix pour cette application.
Dans tous les cas, il est important de trouver le bon équilibre entre le niveau de sortie de l'instrument et le gain du préamplificateur, de l'entrée de Niveau Instrument ou de Niveau Ligne, pour minimiser le bruit et éviter le clipping – soit en poussant le circuit de sortie de l'instrument dans la distorsion, soit en surchargeant l'entrée de la boîte DI, l'entrée de microphone, l'entrée d’instrument ou d’entrée de Niveau Ligne. Un bon point de départ consiste à régler le niveau de sortie de l’instrument à environ 70 % de sa valeur maximale, bien que le niveau réel du signal dépende du patch, de l’échantillon ou du clip utilisé.
![]()
[Concernant les patches, échantillons et clips utilisés lors des performances en direct, il est toujours bon de régler le niveau de sortie de chaque élément afin qu’il ait un niveau perçu similaire aux autres. Cela peut être fait à l’oreille ou avec un mètre SPL placé devant l’amplificateur de l’instrument, avec le niveau souhaité enregistré dans la mémoire utilisateur comme partie de chaque patch, échantillon ou clip. Cela simplifie la vie de l’artiste sur scène en minimisant le besoin d’ajuster le volume après chaque changement tout en essayant de jouer sa partie. Cela, à son tour, facilite le travail de l’ingénieur du son en direct, et les deux améliorations résultent en un concert de meilleure qualité.]
________________________________________
Qu'est-ce qu'un signal ?
Des livres entiers ont été écrits sur les signaux audio et les nombreuses façons dont nous pouvons les définir et les mesurer.
L'onde sinusoïdale est le signal le plus simple de tous (à part le silence absolu) et pourtant, il existe au moins quatre façons de définir son niveau, ou plus précisément, son amplitude. L'illustration ci-dessous montre un cycle d'une onde sinusoïdale (verte) avec une amplitude positive maximale de +1 et une amplitude négative maximale de -1. Elle montre également quatre différentes façons de mesurer et de définir l'amplitude de l'onde sinusoïdale, comme expliqué ci-dessous.
![]()
Crête-à-Crête (Peak-To-Peak)
Commençons par la droite de l'illustration avec Peak-To-Peak, qui est mesuré depuis le sommet de la demi-onde positive jusqu'au sommet de la demi-onde négative. Dans cet exemple, il a une valeur de deux (de +1 à -1), mais il est important de noter qu'à aucun moment la forme d'onde du signal n'atteint réellement la valeur de deux. En fait, dans cet exemple – qui utilise une forme d'onde symétrique où les demi-cycles positif et négatif sont des images miroir – l'amplitude la plus élevée qu'il atteindra est la moitié de la valeur Peak-To-Peak.
Les mesures Peak-To-Peak sont généralement indiquées par le suffixe « pp », par exemple « 2Vpp ». Les mesures Peak-To-Peak sont surtout utilisées pour déterminer ce qu'on appelle souvent l'amplitude du signal ; en d'autres termes, la différence entre l'amplitude positive maximale et l'amplitude négative maximale. L'onde sinusoïdale de l'illustration a une amplitude de deux volts. Ces mesures Peak-To-Peak sont utiles lorsqu'on conçoit des haut-parleurs et des alimentations pour des circuits audio, mais elles ne sont pas vraiment utiles dans notre cas.
Crête (Peak)
Comme on le voit dans l'illustration, la valeur Peak est mesurée depuis zéro jusqu'au sommet maximal positif ou négatif du signal. Dans l'illustration, il est mesuré au sommet positif maximal et a une valeur de +1. Comme l'onde sinusoïdale est une forme d'onde symétrique, on peut supposer que le pic négatif sera de la même valeur que le pic positif (à moins qu'il n'y ait un décalage continu), mais avec une polarité inversée. Contrairement à la valeur Peak-To-Peak, on peut voir que la forme d'onde du signal atteint réellement le niveau Peak – bien que de manière momentanée.
Les mesures Peak sont généralement indiquées par le suffixe « p », par exemple « 1Vp ». Les mesures Peak sont utiles pour déterminer à quel point un signal est proche du niveau maximal d'un appareil, c'est-à-dire le niveau maximal possible avant que la distorsion due au clipping ne se produise. Elles sont couramment utilisées dans les compteurs des équipements audio numériques, où 0dB est le niveau maximal avant le clipping. Les systèmes de mesure Peak considèrent les valeurs Peak des deux côtés de la forme d'onde (c'est-à-dire, les demi-cycles positif et négatif) pour s'assurer que rien ne dépasse à cause d'une forme d'onde non symétrique ou d'un décalage continu.
Moyenne et RMS
Le problème avec les mesures Peak est que de nombreux signaux audio (y compris l'onde sinusoïdale dans l'illustration) ne sont à leur niveau Peak que pendant une brève portion de leur durée. Une mesure Peak fournit une bonne indication de l'amplitude la plus élevée atteinte par le signal, ce qui est utile pour prévenir la distorsion due au clipping, mais elle ne nous dit pas grand-chose d'autre sur le signal – par exemple, à quel point il sera perçu comme fort par rapport à d'autres signaux ayant la même valeur Peak, ce que l'on appellerait son loudness/sonie relatif perçu. Pour des valeurs qui nous permettent de comparer le loudness/sonie relatif de différents signaux, les mesures Moyenne et RMS sont plus utiles que les mesures Peak.
La valeur Moyenne pour une onde sinusoïdale se calcule de la manière suivante :
Moyenne = 0,637 x Pic
Les mesures Moyenne sont généralement indiquées par le suffixe « av », par exemple « 0,637Vav ». L'onde sinusoïdale dans l'illustration ayant une amplitude Peak de 1V, son amplitude Moyenne est :
0,637 x 1 = 0,637Vav
RMS est l'acronyme de Root Mean Square (moyenne quadratique), ce qui décrit le processus mathématique utilisé pour en déterminer la valeur. Les ingénieurs électriques l'appelaient autrefois la heating value, ce qui donne un indice sur ses origines. La valeur RMS pour une onde sinusoïdale se calcule de la manière suivante :
RMS = 0,7071 x Pic
Les mesures RMS sont généralement indiquées par le suffixe « rms », par exemple « 0,7071Vrms ». L'onde sinusoïdale dans l'illustration ayant une amplitude Peak de 1V, son amplitude RMS est :
0,7071 x 1 = 0,7071Vrms
Les mesures données en dBu, comme indiqué précédemment dans cet article, sont basées sur les valeurs RMS où 0dBu = 0,775Vrms. Une valeur de -20dBu signifie que le signal est 20dB plus bas que 0dBu, ce qui signifie qu'il est 20dB plus bas que 0,775Vrms, soit 0,0775Vrms. Comme astuce rapide pour les dB, il est bon de savoir que 20dB représente un facteur de 10, donc -20dB signifie ÷10, et +20dB signifie x10. Ainsi, -20dBu est 1/10e de 0dBu, ce qui est 1/10e de 0,775Vrms.
Notez que les formules pour les valeurs Moyenne et RMS ci-dessus ne s'appliquent qu'aux ondes sinusoïdales. Les formules de calcul des valeurs Moyenne et RMS pour d'autres formes d'ondes deviennent de plus en plus complexes à mesure que la forme d'onde devient complexe.
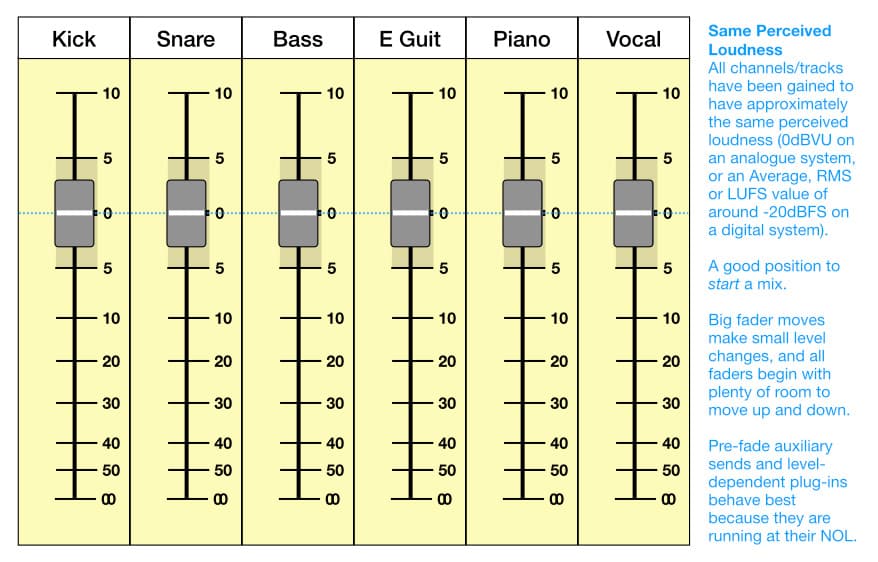
Pour les applications audio, les valeurs Moyenne et RMS donnent toutes deux une meilleure indication du loudness/sonie relatif perçu d'un signal. Cependant, aucune des deux n'est aussi efficace que le système de mesure LUFS lorsqu'il s'agit de comparer et d'ajuster le loudness/sonie relatif perçu de différents signaux. Tu as probablement entendu parler des LUFS (Loudness Units Full Scale) en référence au mastering des mixes pour les services de streaming. Le loudness/sonie perçu est généralement un sujet de mastering, donc en quoi cela concerne-t-il le choix des microphones et la configuration du gain ? Continue à lire...
Microphones, Gain et loudness/sonie?
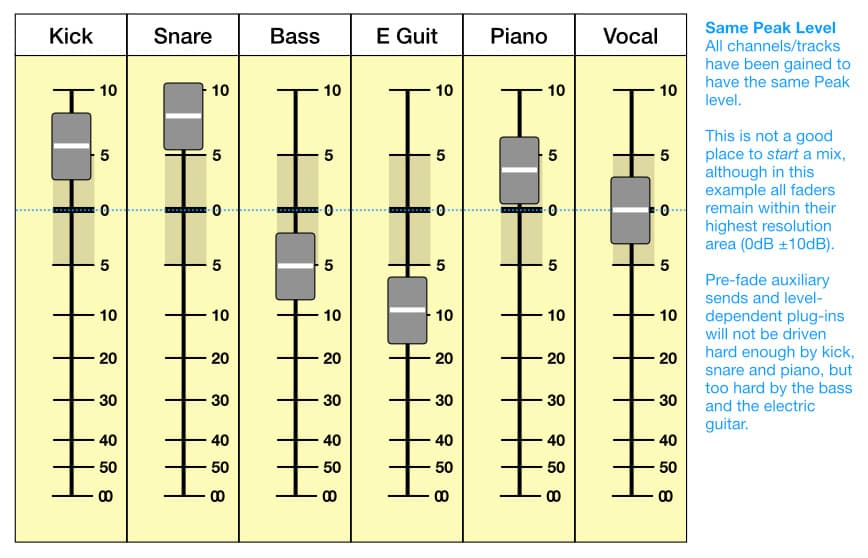
Tous les appareils audio numériques possèdent une mesure Peak pour nous aider à empêcher les niveaux de signal de dépasser le niveau maximal (0dBFS) et de provoquer de la distorsion. Certaines DAWs (stations de travail audio numériques) offrent également des mesures RMS et/ou Moyenne qui sont généralement superposées à la mesure Peak, et il existe des plug-ins et des applications qui proposent de nombreuses options de mesure.
Nous ne pouvons pas utiliser les niveaux Peak pour comparer le loudness/sonie perçu de différents signaux audio, car le système auditif humain ne prête pas beaucoup d'attention aux pics de courte durée comme ceux trouvés dans un son percussif. Au contraire, il évalue la loudness/sonie d'un son en utilisant un système de moyenne complexe qui nécessite des capacités de traitement de signal importantes pour l’émuler.
![]()
C'est une excellente illustration de la façon dont la loudness/sonie perçue diffère des niveaux de Pic dans les signaux audio !
Lorsque nous regardons ces deux formes d'onde, bien que la voix et le kick aient les mêmes niveaux de Pic (les points les plus élevés atteints par chaque forme d'onde), elles n'ont pas la même loudness/sonie perçue. La raison en est que la loudness/sonie perçue est influencée non seulement par le niveau de Pic, mais aussi par la durée, le spectre de fréquence et les transitoires présents dans le son.
• Piste vocale : Les voix ont généralement un spectre de fréquences plus large qui correspond à la plage de sensibilité de l'audition humaine. Nos oreilles sont plus sensibles aux fréquences moyennes (où se trouvent la plupart des voix) qu'aux sons de basse fréquence, ce qui rend la voix perçue comme plus forte, même si son niveau de Pic est plus bas que celui d'un kick.
• Kick : Bien que le kick puisse avoir un niveau de Pic plus élevé que la voix, une grande partie de son énergie est concentrée dans des pics de courte durée (transitoires) et des fréquences basses, où l'audition humaine est moins sensible. Cela fait que le kick semble plus faible en termes de loudness/sonie perçue, même si son niveau de Pic est plus élevé.
Ainsi, dans la deuxième illustration où le niveau de la voix a été réduit pour correspondre à la loudness/sonie perçue du kick, le niveau de Pic du kick est beaucoup plus élevé, mais la loudness/sonie perçue est similaire. Cela nous aide à comprendre pourquoi différents instruments ou sons dans un mix peuvent ne pas toujours correspondre à leurs niveaux de Pic en ce qui concerne la façon dont ils sont perçus comme forts ou faibles.
Cette différence est également la raison pour laquelle la mesure en LUFS (Loudness Units relative to Full Scale) est une méthode plus précise pour mesurer la loudness/sonie perçue, car elle prend en compte la sensibilité aux fréquences et la pesée dans le temps pour mieux correspondre à la façon dont nous percevons le son.
![]()
Facteur de crête (Crest Factor)
En termes audio, le Crest Factor (facteur de crête) d'un signal décrit la différence entre le niveau Peak (crête) et le niveau Moyenne d'un signal, et est généralement exprimé en décibels. Les sons percussifs (comme la grosse caisse dans les exemples ci-dessus) ont un niveau Peak élevé, mais un niveau Moyenne faible, ce qui leur donne un Crest Factor élevé, mais une faible loudness/sonie perçue. En comparaison, les sons non percussifs (comme la voix dans les exemples ci-dessus) ont un Crest Factor beaucoup plus faible, ce qui permet un niveau Moyenne plus élevé et donc une loudness/sonie perçue plus forte.
Un signal avec un Crest Factor élevé aura besoin de plus d'Headroom (voir ci-dessous) qu'un signal avec le même niveau Moyenne mais un Crest Factor plus faible.
Lors du mastering audio pour se conformer aux exigences de plage dynamique limitée des services de streaming, l'un des objectifs est de réduire le Crest Factor du signal afin que le niveau Peak soit plus bas. Cela permet d'augmenter le niveau Moyenne – ce qui augmente ainsi la loudness/sonie perçue.
VU & LUFS
Le problème de l'indication de la loudness/sonie perçue nous a donné le VU meter (voltmètre), dans les années 1930, comme moyen de maintenir une loudness/sonie constante dans les applications de diffusion, où le matériel programmatique passait régulièrement d'une voix d'annonceur à une autre ou à différents morceaux de musique. « VU » signifie Volume Unit (unité de volume), où volume fait référence à la loudness/sonie perçue, et non à un espace cubique. Le VU meter utilise des mesures ballistiques relativement lentes (c'est-à-dire la vitesse à laquelle l'aiguille peut se déplacer) avec des temps d'attaque et de relâchement d'environ 300 ms (0,3 s), ce qui lui confère un effet de moyennage. L'aiguille bouge trop lentement pour suivre les pics transitoires de la grosse caisse montrée précédemment, ce qui provoque une perception tronquée de ces niveaux de loudness/sonie perçues. L'idée de base est (ou était) que si tous les signaux envoyés à l'antenne ont à peu près le même niveau sur le VU meter, alors ils devraient avoir une loudness/sonie perçue à peu près équivalente. Il ne devrait donc y avoir aucune surprise soudaine lors du passage entre les voix des annonceurs et/ou la musique populaire de l'époque. Le VU meter fonctionnait assez bien pour cette application, mais ses limites sont devenues évidentes avec l'introduction de l'enregistrement multitrack et de la prise de son rapprochée (close miking) des instruments de musique individuels, en particulier lors du travail avec des sons percussifs/ pincés ayant des transitoires rapides et des décays courts, comme la grosse caisse montrée plus tôt.
Les systèmes de diffusion numérique contemporains sont confrontés au même problème que les premiers diffuseurs analogiques, sauf qu'ils doivent passer d'un type de source sonore à l'autre (narration/dialogue, différents genres de musique et sons, films, etc.) à la demande, et contrairement aux premiers diffuseurs, il n'y a pas d'ingénieur qui surveille ce qui est "diffusé" en temps réel pour effectuer des ajustements lorsque les niveaux sont trop forts ou trop faibles. Cela a conduit à l'affinement du système de mesure LUFS, tel que décrit dans la norme EBU R128 et basé sur les recommandations de l'ITU BS1770. C'est un indicateur bien plus précis de la loudness/sonie perçue que le VU meter ; si deux signaux ont la même valeur LUFS intégrée (c'est-à-dire la moyenne sur la durée du signal), ils auront probablement la même loudness/sonie perçue en général. Les services de streaming ont adopté des niveaux LUFS intégrés spécifiques pour maintenir une loudness/sonie constante lors de la lecture – c'est pourquoi vous pouvez généralement passer d'une vidéo à l'autre sur YouTube ou entre plusieurs morceaux de musique sur Spotify sans subir de changements importants dans la loudness/sonie perçue. La mesure LUFS intégrée peut fournir des indications très précises de la loudness/sonie perçue, mais quel rapport cela a-t-il avec le choix des microphones et le réglage du gain ? Continuez à lire…
![]()
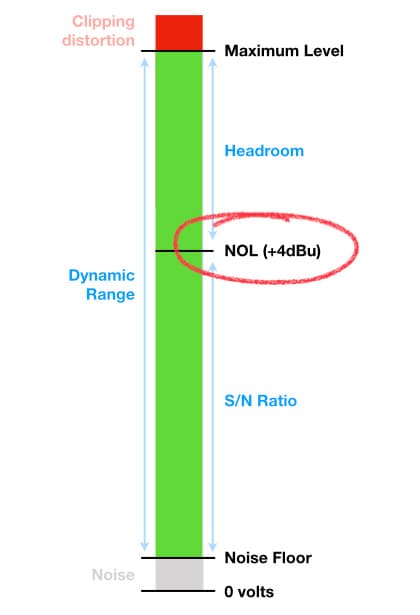
Niveau de Fonctionnement Nominal (Nominal Operating Level - NOL)
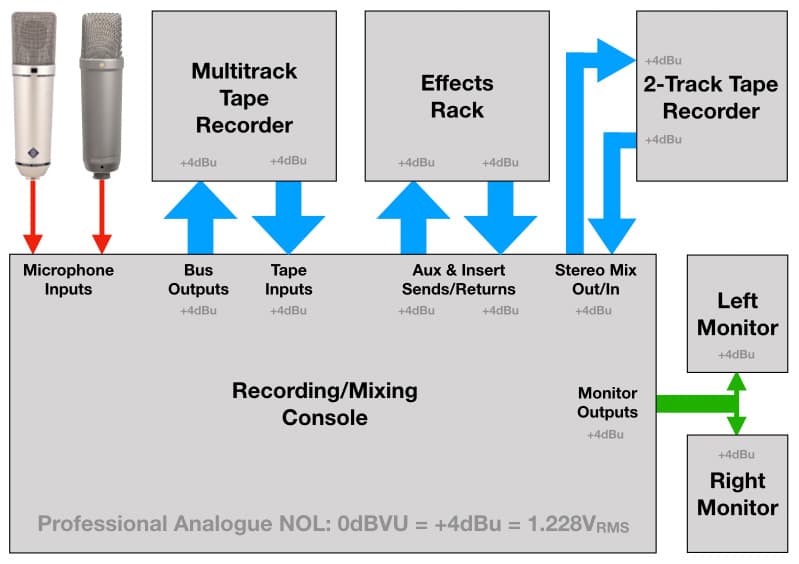
Les VU meters sont toujours populaires sur les appareils audio analogiques, et tous les appareils audio analogiques partagent les limitations de bruit et de distorsion mentionnées précédemment. Le bruit est un problème lorsque le niveau du signal devient trop faible, et la distorsion est un problème lorsque le niveau du signal devient trop élevé. Parce que les signaux audio peuvent varier considérablement entre leurs niveaux de Peak et leurs niveaux perçus (qu'ils soient mesurés en Moyenne, RMS ou LUFS), les équipements audio analogiques professionnels suivent un concept connu sous le nom de Niveau de Fonctionnement Nominal (NOL) – un niveau de signal recommandé qui est suffisamment élevé pour que le niveau perçu soit au-dessus du bruit, mais (idéalement) suffisamment bas pour empêcher que le niveau de Peak ne provoque de distorsion due au clipping. Le NOL est représenté par 0dB sur un VU meter et est donc appelé 0dBVU. Les signaux qui se trouvent au niveau du NOL sont également appelés Line Level, comme mentionné précédemment.
Dans les équipements audio analogiques professionnels, le NOL de 0dBVU est normalisé à un niveau de signal de +4dBu, ce qui est équivalent à une tension de 1.228VRMS lorsqu'il est mesuré à l'aide d'une onde sinusoïdale de 1 kHz comme signal. Autrement dit, si une onde sinusoïdale de 1 kHz est passée à travers l'équipement et que son niveau est ajusté pour lire 0dBVU sur le VU meter, elle aura une tension de 1.228VRMS. Cette norme permet à tous les éléments du studio d'enregistrement analogique d'être calibrés sur le même NOL de +4dBu, de sorte que 0dBVU à la sortie de la console de mixage donne 0dBVU à l'entrée des enregistreurs à bande et des processeurs d'effets, et vice versa. Lorsque tout est calibré sur le même NOL, tous les appareils individuels du système audio analogique deviennent essentiellement un seul et grand appareil intégré. Si nous réglons correctement le niveau au préamplificateur, il devrait être correct pour le reste du système – du moins jusqu'à ce que nous commencions à pousser les faders loin de leurs positions 0dB (ou Unity/Unité), à appliquer de l'égalisation, à utiliser de la compression et à faire d'autres actions qui affectent le niveau du signal.
Si nous connaissons le NOL d'un appareil audio analogique, ainsi que son Niveau Maximum (le niveau où la distorsion due au clipping se produit) et son Noise Floor (le niveau de son bruit), nous pouvons calculer ses spécifications pour la Plage Dynamique, le S/N Ratio et le Headroom, comme indiqué ci-dessous.
![]()
Le Niveau de Fonctionnement Nominal (NOL) est un concept essentiel dans les équipements audio, garantissant le meilleur équilibre entre la force du signal, le bruit et la distorsion. Il est généralement représenté par 0dBVU sur un mètre VU, qui, pour les équipements audio analogiques professionnels, est standardisé à un niveau de signal de +4dBu. Le +4dBu correspond à une tension de 1.228VRMS lorsqu'il est mesuré avec une onde sinusoïdale de 1 kHz.
Ce NOL standardisé garantit que les appareils audio dans une chaîne d'enregistrement ou de diffusion sont calibrés à un même niveau de signal, ce qui aide à maintenir des niveaux audio cohérents à travers le système. Par exemple, un signal réglé pour afficher 0dBVU sur le mètre VU correspondra à +4dBu lorsqu'il passe par un équipement analogique professionnel, fournissant une référence pour tous les appareils connectés à s'aligner.
Application Pratique
Lorsque tous les équipements sont calibrés au même NOL (par exemple, +4dBu), il devient plus facile de travailler avec divers appareils dans une configuration de studio analogique, comme les consoles de mixage, les enregistreurs à bande et les processeurs d'effets. Si le niveau est correctement réglé à l'étape du préamplificateur, il devrait se propager de manière cohérente dans tout le système, sauf si d'autres facteurs comme l'EQ, la compression ou les ajustements de fader modifient le niveau du signal.
Cependant, pour atteindre le bon équilibre et une performance optimale, il est nécessaire de prendre en compte la Plage Dynamique, le Rapport Signal/Bruit (S/N) et la Marge de Sécurité de chaque appareil dans la chaîne audio. Ces facteurs contribuent à maintenir un signal suffisamment fort pour éviter la distorsion (clipping), tout en restant suffisamment au-dessus du niveau de bruit pour garantir une bonne qualité sonore.
Plage Dynamique, Rapport Signal/Bruit et Marge de Sécurité
• Plage Dynamique : La différence entre les parties les plus silencieuses et les plus fortes du signal audio. Dans un contexte professionnel, cette plage doit être suffisamment large pour éviter la distorsion tout en permettant aux sons faibles de rester audibles et clairs.
• Rapport Signal/Bruit (S/N) : Le rapport entre le niveau du signal et le niveau de bruit de fond. Un rapport S/N plus élevé signifie que le signal est beaucoup plus clair par rapport au bruit de fond, ce qui est crucial dans les équipements audio professionnels pour éviter le souffle ou les ronflements qui altéreraient la qualité sonore globale.
• Marge de Sécurité : L'espace entre le niveau moyen du signal et le niveau maximum avant que la distorsion ou le clipping n'intervienne. Cela est essentiel pour éviter la distorsion, en particulier lorsqu'il y a des pics inattendus dans le signal audio, comme dans les sons percussifs ou les pics soudains de volume.
Relation avec les Microphones
Dans les chapitres précédents, nous avons discuté de la manière dont les microphones interagissent avec ces concepts, en particulier comment leur niveau de sortie doit être amplifié au Niveau Ligne par les préamplificateurs et comment régler correctement le gain aide à maintenir le bon niveau de signal à travers le système. Un bon réglage du gain garantit que le signal du microphone reste au-dessus du niveau de bruit, mais ne dépasse pas le niveau maximum du système, où la distorsion pourrait se produire.
Impact sur le Chemin du Signal
En respectant le Niveau de Fonctionnement Nominal (NOL) de +4dBu, vous vous assurez que le signal audio conserve sa clarté, sa cohérence et sa qualité tout au long de son parcours, du microphone à la sortie finale. Cependant, il est important de prêter attention au Niveau Maximum de l'équipement, où commence la distorsion, ainsi qu'au Niveau de Bruit, afin de prévenir la dégradation de la qualité sonore. Comprendre les spécifications de Plage Dynamique, de Rapport Signal/Bruit et de Marge de Sécurité de chaque appareil audio vous aidera à prendre de meilleures décisions lors du routage des signaux et des réglages du gain pour obtenir une performance optimale.
Rapport Signal/Bruit (S/N Ratio)
Dans les précédentes sections, nous avons vu que la spécification du Rapport Signal/Bruit (S/N Ratio) du microphone est définie comme la différence entre 94dB SPL et le niveau de bruit équivalent du microphone ou le bruit propre. Un SPL de 94dB au niveau du diaphragme était utilisé comme point de référence pour représenter le signal. Dans les équipements audio analogiques professionnels, le point de référence est le Niveau de Fonctionnement Nominal (NOL) de l'appareil, et le Rapport Signal/Bruit est défini comme la différence entre le NOL et le niveau de bruit de l'appareil. Il est spécifié en dB, et une valeur plus élevée signifie un meilleur rapport S/N – c'est-à-dire un bruit plus faible. Comme montré dans l'illustration précédente :
S/N Ratio = Niveau de Fonctionnement Nominal - Niveau de Bruit
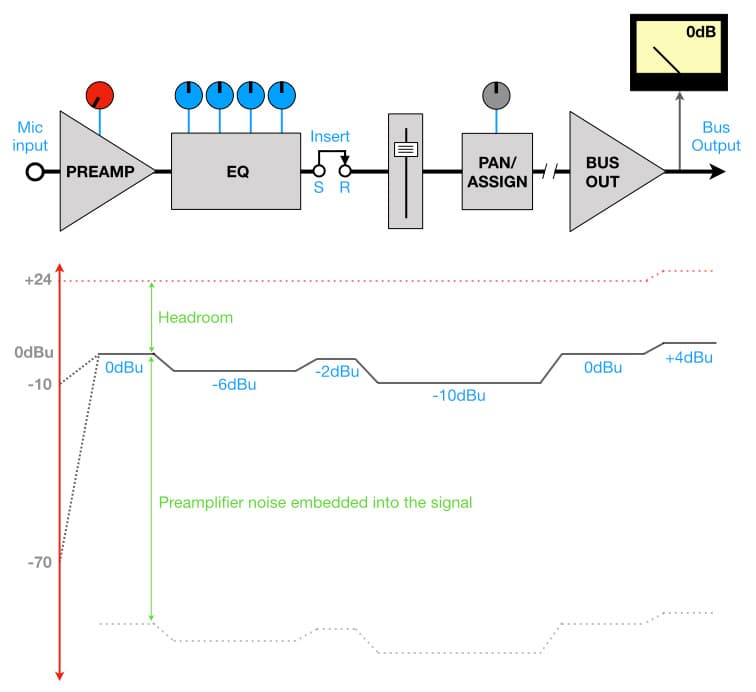
Headroom (Marge de Sécurité/ plafond)
La spécification de la Marge de Sécurité décrit la différence entre le NOL d'un appareil et son Niveau Maximum. En d'autres termes, cela montre jusqu'à quel point le signal peut dépasser le NOL avant d'atteindre le clipping. Comme illustré précédemment :
Headroom = Niveau Maximum - Niveau de Fonctionnement Nominal
La plupart des équipements audio analogiques professionnels offrent au moins 20dB de Marge de Sécurité, et tout ce qui est inférieur est généralement considéré comme insuffisant. C’est une information utile que nous reviendrons voir plus tard lorsque nous examinerons comment les équipements numériques s’intègrent dans le monde analogique du son. Pour un NOL donné, plus la Marge de Sécurité est grande, mieux c’est. Les mesureurs de crête (Peak meters) présents sur les appareils audio numériques sont parfois appelés "mesureurs de Marge de Sécurité" car ils montrent combien de Marge de Sécurité reste entre le pic du signal et le niveau maximum de l'appareil.
La Marge de Sécurité est rarement, voire jamais, mentionnée pour les microphones, mais elle peut être calculée à partir de la spécification du SPL Maximum du microphone, moins 94dB SPL. En essence, nous pouvons utiliser 94dB SPL comme le Niveau de Fonctionnement Nominal du microphone, tout comme lors du calcul du Rapport Signal/Bruit du microphone.
Plage Dynamique
Dans l'édition précédente, nous avons vu que la spécification de la Plage Dynamique du microphone décrivait la différence entre le niveau de son bruit et la spécification de son SPL Maximum (le point où le clipping se produit). La même logique s'applique à la Plage Dynamique des équipements audio analogiques professionnels – elle est définie comme la différence entre le Niveau de Bruit de l'appareil et son Niveau Maximum. Elle est spécifiée en dB, et une valeur plus grande signifie que l'appareil possède une Plage Dynamique plus large, ce qui peut aussi signifier un meilleur Rapport S/N, plus de Marge de Sécurité, ou les deux. Comme montré dans l'illustration précédente :
Plage Dynamique = Niveau Maximum - Niveau de Bruit
Et aussi comme indiqué dans l'illustration :
Plage Dynamique = Marge de Sécurité + Rapport S/N
Niveau d'Alignement (Alignment Level)
Les choses sont différentes dans le monde numérique. Le bruit inhérent aux systèmes numériques est tellement faible comparé au bruit d'un système analogique (surtout lorsqu'on utilise des enregistreurs à bande analogiques) que la nécessité d'un NOL n'est pas immédiatement évidente. La principale exigence est de s'assurer que le niveau de crête du signal ne dépasse pas le niveau maximum du système numérique, qui est représenté par 0dBFS sur le mesureur numérique du système. Le "FS" dans "dBFS" signifie Full Scale, où 0dBFS représente le Niveau Maximum (ou niveau de clipping) et le dépasser entraîne de la distorsion. À l'exception de 0dBFS, tous les autres niveaux dBFS sont donnés en nombres négatifs, représentant la distance entre le niveau de crête du signal et le niveau maximum. Par exemple, un niveau de -12dBFS signifie que le niveau de crête du signal est à 12dB en dessous du niveau où se produit le clipping. Cela semble simple, mais il y a plus à comprendre…
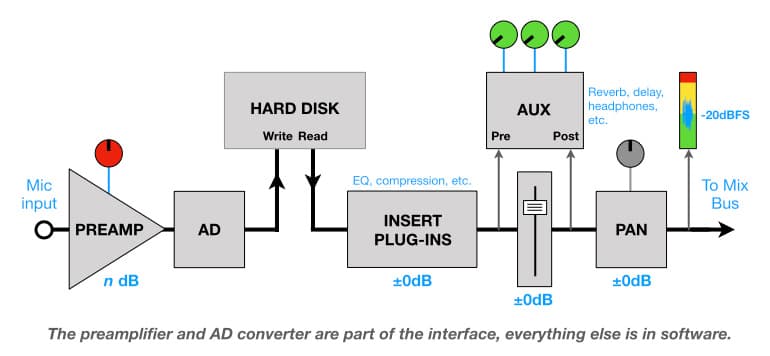
À un certain moment, nous devons introduire un signal analogique dans le système numérique depuis nos microphones et autres sources sonores analogiques, et à un autre moment, nous devons sortir un signal analogique du système numérique pour le connecter à des casques, des moniteurs ou des processeurs analogiques externes. Cela signifie que le système numérique doit finalement avoir des circuits d'entrée et/ou de sortie analogiques (c'est-à-dire des convertisseurs analogique-numérique et numérique-analogique), et pour les parties analogiques de ces circuits, toutes les spécifications analogiques mentionnées précédemment restent valables. De plus, si notre équipement numérique professionnel doit être intégré avec notre équipement analogique professionnel (par exemple, utiliser un DAW avec une console de mixage analogique ou un processeur, ou utiliser des plug-ins qui modélisent des processeurs analogiques vintage), il doit avoir un équivalent numérique du NOL de l'équipement analogique professionnel – un niveau de référence qui se conforme à +4dBu tout en permettant suffisamment de marge pour le signal provenant des dispositifs analogiques. Cela est généralement appelé un Niveau d'Alignement, et c'est l'équivalent numérique du NOL du système analogique.
0dBFS ? 0dBVU
La plupart des premiers enregistreurs numériques multipistes (par exemple, Sony 3348, Mitsubishi X850) conçus pour être utilisés dans des studios multipistes analogiques avaient des niveaux d'alignement compris entre -19dBFS et -24dBFS pour +4dBu, ce qui permettait de maintenir le NOL du studio analogique et de les installer directement à la place d'un enregistreur multipistes analogique. Comme avantage supplémentaire, ils offraient plus de Marge de Sécurité que les enregistreurs à bande analogiques qu'ils remplaçaient, lesquels n'offraient que rarement plus de 12dB au-dessus du NOL (0dBVU) avant d'entrer en saturation de la bande – l'équivalent magnétique du clipping, qui peut être euphonique à petites doses.
Un problème intéressant avec les premiers enregistreurs numériques multipistes était que, bien que leurs entrées et sorties se conforment au concept de NOL +4dBu du studio analogique, leur mesureur utilisait l'échelle dBFS où 0dBFS représente le Niveau Maximum – ce qui n'est pas le même que le NOL représenté par 0dBVU.
![]()
Cela a créé de la confusion chez les ingénieurs du son expérimentés qui avaient affiné leurs compétences dans un monde où les niveaux de signal devaient être maintenus autour de 0dB sur un système de métrologie conçu pour afficher une forme de loudness/sonie perçue relative (le mètre VU), et où il y avait toujours de la Marge de Sécurité pour aller au-dessus de 0dB. Comment transférer leurs compétences de réglage de niveau dans un système de métrologie numérique où 0dB est le niveau maximum et ne peut pas être dépassé ?
La fidélité à la vieille règle analogique de garder les niveaux de signal aussi proches que possible de 0dB, combinée à la nouvelle règle numérique de ne pas laisser le signal dépasser 0dB, a mis en évidence les malentendus entre 0dBVU et 0dBFS. Dans de nombreux studios hybrides des premiers temps (consoles analogiques avec enregistreurs multipistes numériques), les sorties des bus de la console étaient souvent poussées 12dB ou plus au-dessus du NOL de 0dBVU pour rapprocher les niveaux de signal de 0dBFS sur les mètres des enregistreurs numériques, comme les ingénieurs pensaient qu'ils devaient faire en maintenant les niveaux proches de 0dB.
Gritty-Sweet 16
Les préoccupations concernant les tailles de mots en 16 bits et le traitement étaient souvent écartées par l'idée qu'il n'était pas nécessaire d'aller au-delà de 16 bits, car c'était le meilleur que le CD puisse offrir – une justification mathématiquement mal informée qui allait à l'encontre d'une des vérités les plus anciennes du monde de l'audio : que les équipements de capture et de production doivent toujours avoir de meilleures spécifications que le support de diffusion, car chaque étape du processus de production réduit la qualité, particulièrement en termes de bruit. Dans le monde analogique, le bruit accumulé des processus d'enregistrement, de production et de mastering (bruit de la salle, bruit thermique, souffle de la bande, bruit de surface du lacquer et du stamper) ne posait pas de problème tant qu'il restait suffisamment bas par rapport au bruit des supports de diffusion, c'est-à-dire le bruit de surface du vinyle pressé ou le souffle de la cassette. La même chose est vraie dans le monde numérique, sauf que le bruit des systèmes numériques (bruit thermique des circuits d'entrée et de sortie analogiques, bruit de quantification lors de la conversion et du traitement, bruit de dithering ajouté pour dé-corréler et masquer le bruit de quantification) est bien plus faible dès le départ, ce qui en fait rarement un problème, même après un traitement considérable.
Pour mieux comprendre cela, certains des premiers studios à adopter des enregistreurs numériques multipistes ont rapidement découvert que le bruit de fond de leurs espaces d'enregistrement et le bruit de leurs consoles (qui était auparavant masqué par le souffle de la bande analogique) étaient désormais audibles dans leurs enregistrements et pouvaient être entendus s'accumulant avec chaque nouvelle piste. C'était un problème intéressant – retirer le bruit de la bande analogique a mis en évidence ce qui était caché.
De même, lors de l'utilisation des premiers systèmes multipistes entièrement numériques qui utilisaient la technologie 16 bits, l'erreur de quantification accumulée et sa "rugosité" associée sont devenues évidentes en l'absence de tout bruit analogique (par exemple, bruit thermique de la console de mixage analogique) pour la cacher ou la dé- corréler via un dithering accidentel – ce qui explique pourquoi cette "rugosité" ne posait pas de problème dans les premiers studios hybrides utilisant des consoles de mixage analogiques avec des enregistreurs multipistes numériques 16 bits. [Cela explique aussi en partie le phénomène des "mixeurs de sommation", mais c'est une autre histoire…]
Qu'est-ce que tout cela a à voir avec le choix des microphones et le réglage du gain ? Cela met en lumière l'histoire de certains malentendus tenaces concernant les niveaux de signal dans les systèmes audio numériques, et il est crucial de bien régler les niveaux de signal dans les systèmes audio numériques lors du choix des microphones et du réglage du gain – comme nous allons le voir sous peu.
RP-155
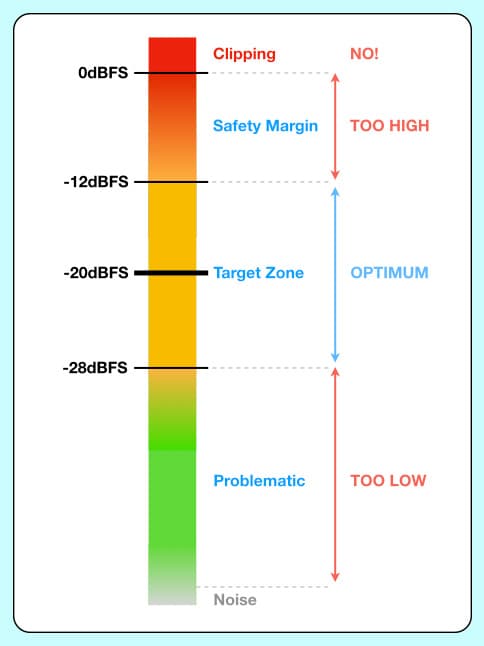
Au début des années 1990, la SMPTE (Society of Motion Picture and Television Engineers) a proposé la norme RP-155 qui recommande un Niveau d'Alignement de -20dBFS. Selon RP-155, si une onde sinusoïdale de 1kHz à +4dBu entre dans l'entrée ligne analogique de l'appareil numérique, son mètre devrait afficher -20dBFS, et si cette même onde sinusoïdale à -20dBFS sort de la sortie ligne analogique de l'appareil numérique, elle devrait mesurer +4dBu. RP-155 donne au système numérique 20dB de Marge de Sécurité, ce qui est suffisant pour la plupart des applications musicales et de dialogue.
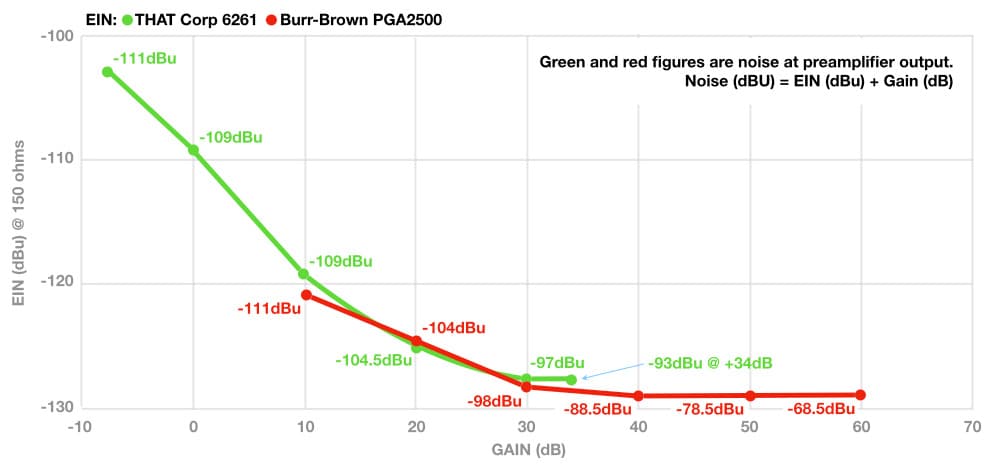
Comment les spécifications analogiques mentionnées précédemment s'intègrent-elles dans un système de mesure numérique aligné selon RP-155 ? Nous savons déjà que le Niveau Maximum du système numérique (0dBFS) et son Niveau d'Alignement (-20dBFS, équivalent au NOL dans le monde analogique), ce qui signifie que nous pouvons calculer sa Marge de Sécurité (20dB). Pour calculer le Rapport Signal/Bruit d'un système numérique, nous devons connaître sa Plage Dynamique, que nous pouvons calculer si nous connaissons sa taille de mot (bitword)…
La forme la plus courante de l'audio numérique, utilisée dans les CD et les fichiers wav, est appelée Linear PCM (ou LPCM ou simplement PCM). Calculer la Plage Dynamique pour un système Linear PCM est simple : elle est de 6.0206dB par bit, bien que cela soit couramment arrondi à une valeur de référence de 6dB par bit. Nous utiliserons 6dB par bit pour cet exercice. Un fichier wav de 24 bits offre une Plage Dynamique de 24 x 6 = 144dB, ce qui dépasse facilement ce que les circuits analogiques pratiques peuvent offrir. Si la Plage Dynamique est de 144dB et que le niveau maximum est 0dBFS, le niveau minimum sera -144dBFS. En tenant compte de quelques dB dus au bruit d'erreur de quantification et au dithering, cela donne un Niveau de Bruit qui se situe toujours quelque part en dessous de -140dBFS.
L'illustration ci-dessous montre comment les spécifications analogiques mentionnées précédemment s'intègrent dans un système numérique 24 bits et un système numérique 16 bits, tous deux alignés selon RP-155 afin que -20dBFS = +4dBu.
![]()
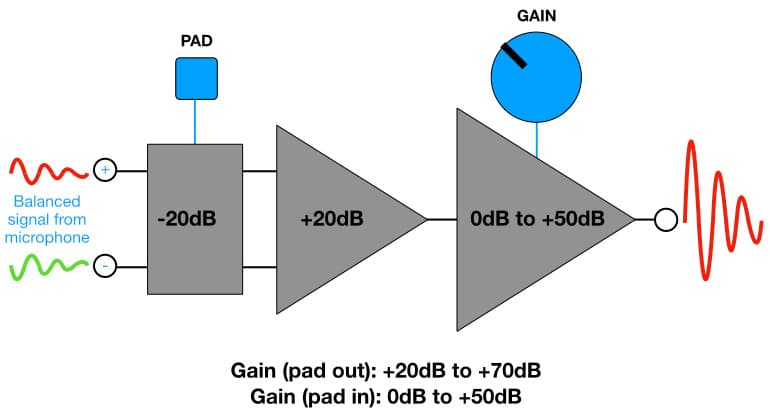
Connaître ces informations permet d'optimiser les systèmes qui combinent équipements analogiques et numériques. Par exemple, utiliser le Niveau d'Alignement recommandé par RP-155 de -20dBFS pour un enregistreur numérique a du sens si le préamplificateur du microphone qui l'alimente dispose également de 20dB de Marge de Sécurité – les deux appareils ont le même Niveau Maximum, les deux entreront en clipping en même temps et aucun des deux ne gaspille sa capacité de Marge de Sécurité.
Si le préamplificateur du microphone était un appareil plus coûteux avec 24dB de Marge de Sécurité, il serait alors logique de régler le Niveau d'Alignement de l'enregistreur numérique à -24dBFS, sinon nous gaspillons les capacités de Marge de Sécurité du préamplificateur, car l'enregistreur numérique entrera en clipping avant le préamplificateur.
![]()
Marge de Sécurité (Safety Margin)
Alternativement, nous pourrions utiliser la Marge de Sécurité supplémentaire du préamplificateur pour créer une "marge de sécurité", de manière similaire à celle utilisée dans les bandes analogiques qui avaient moins de Marge de Sécurité que le préamplificateur ou la console qui les alimentait, mais qui n'entraient pas instantanément en clipping lorsqu'elles étaient poussées au-delà de leur Marge de Sécurité. Au lieu de cela, elles entraient en saturation de la bande, ce qui, entre autres, offrait un effet de compression léger qui laissait une certaine marge d'erreur avant que le signal devienne inutilisable.
Aligner le préamplificateur et l'enregistreur numérique dans cet exemple de sorte que +4dBu = -20dBFS signifie que le préamplificateur décrit ci-dessus dispose de 4dB de Marge de Sécurité supplémentaire au-dessus du 0dBFS du système numérique. En insérant un compresseur à « knee » raide entre la sortie du préamplificateur et l'entrée de l'enregistreur numérique avec un seuil de +20dBu (-4dBFS sur le système numérique), un ratio de 2:1 et des temps d'attaque et de relâchement très rapides, les derniers 8dB de la Marge de Sécurité du préamplificateur seront compressés dans les derniers 4dB de la Marge de Sécurité du système numérique. Le réglage des niveaux afin d'empêcher les pics de dépasser -4dBFS signifie qu'il y a une marge de sécurité de 8dB dans le préamplificateur qui a été compressée dans les derniers 4dB du système numérique, au cas où un pic de niveau passerait au-delà de -4dBFS. Dans cet exemple, le compresseur aurait évidemment besoin de la même Marge de Sécurité ou d'une plus grande Marge de Sécurité que le préamplificateur, et l'objectif serait de régler le gain pour éviter que les niveaux de crête n'atteignent normalement -4dBFS, de manière à ce que la marge de sécurité soit véritablement une "marge de sécurité". Ce concept peut être appliqué de manière plus subtile, comme nous allons le voir sous peu…
![]()
Niveau Maitrisés et Normalisés
La recommandation RP-155 a été formulée il y a plusieurs années ; le fait qu'elle reste pertinente témoigne de la compréhension traditionnelle de l'audio analogique, qui reconnaît qu'un signal audio n'est pas uniquement défini par son niveau de crête.
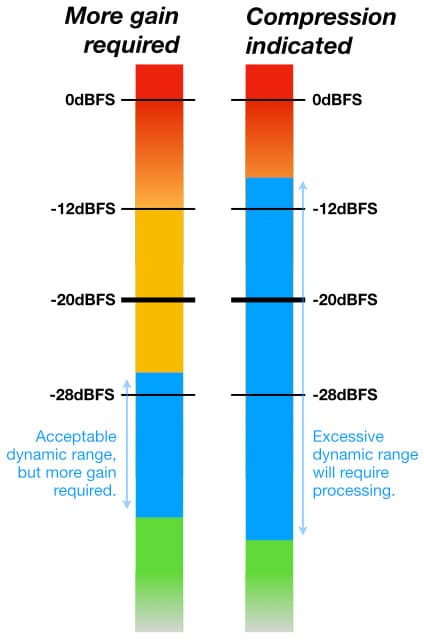
À peu près à la même époque où la recommandation RP-155 a été faite, l'EBU (Union Européenne de Radiodiffusion) a recommandé un Niveau d'Alignement de -18dBFS. Il est 2dB plus élevé que celui de RP-155, offrant ainsi 2dB de marge de sécurité en moins. Cela ne pose pas de problème majeur pour les radiodiffuseurs travaillant avec des voix parlées et des matériaux musicaux déjà maîtrisés. Cependant, cela frôle le seuil d'insuffisance pour travailler avec des instruments de musique enregistrés de près (close-miking), mais en pratique, régler le gain d'un signal musical capté de près pour que son niveau de crête moyen oscille autour de -18dBFS ou -20dBFS tout au long de la performance donne un résultat très similaire – surtout lorsque l'on travaille avec des sources sonores qui peuvent s'éloigner ou se rapprocher du micro pendant l'enregistrement.
Des travaux complémentaires menés par CBS (Columbia Broadcasting System), l'ITU (Union Internationale des Télécommunications) et d'autres ont suggéré des lignes directrices qui intègrent des éléments précieux des systèmes de mesure analogiques bien établis (comme les VU et PPM) dans les systèmes de mesure numériques. Pourquoi cela ? Parce qu'il y a bien plus dans un signal audio que son simple niveau de crête – comme nous le verrons dans la suite…
Microphone : Niveaux et histoire :
https://www.guitariste.com/for(...)03143
Microphone : Sensibilité
https://www.guitariste.com/for(...)03144
Microphone : Niveau et Gain
https://www.guitariste.com/for(...)03144
Microphone : Structure de Gain
https://www.guitariste.com/for(...)03146
Microphone : Hertz et dBs
https://www.guitariste.com/for(...)03147
Microphone : SPL et Distortion
https://www.guitariste.com/for(...)03148
Ce qui suit est la traduction/adaptation d'une série d'article écrit par Greg Simmons.
J'ai utilisé ChatGPT à 99% pour la traduction. J'ai volontairement laissé des anglicismes et des acronymes parce que dans l'audio il y a des anglicismes partout et que certains mots ont des sens différents suivant le contexte. Par exemple clipping c'est une saturation mais un clipping numérique c'est aussi un "rabot"
https://www.audiotechnology.com/tutorials/microphones-tutorials/microphones-levels-history
Microphones : Niveaux et Histoire
Dans ce neuvième volet de cette série, nous examinons les nombreuses façons dont nous pouvons mesurer les niveaux de signal et comment cela peut nous aider à choisir des microphones et à régler le gain.
Par Greg Simmons
9 décembre 2021
Dans les précédents volets, nous avons étudié plusieurs spécifications des microphones et des préamplificateurs liées aux niveaux de signal, toujours dans le but de minimiser le bruit et de réduire la possibilité de clipping dans nos signaux. L'objectif était d'associer la Sensibilité du microphone avec le SPL de la source sonore, afin que le contrôle de gain du préamplificateur n'ait pas besoin d'être trop élevé, ce qui rendrait le bruit plus apparent, mais qu'il ne soit pas non plus trop bas, ce qui indiquerait que la Sensibilité du microphone était trop élevée pour l'application et pourrait surcharger le chemin du signal et créer de la distorsion.

Avant de poursuivre, tu voudras peut-être revoir les quatre premiers volets de cette série pour rafraîchir ta mémoire sur la Sensibilité, le Bruit, le SPL et la Distorsion. Dans l'édition sur la Sensibilité, nous avons introduit le concept de la "Zone de Goldilocks" autour du contrôle de gain du préampli — une zone idéale où il faut garder le contrôle de gain. Dans l'édition sur le Bruit, nous avons étudié les sources de bruit dans le microphone et dans le préamplificateur (Bruit Brownien et Bruit Thermique) et ce que nous pouvons faire pour minimiser le bruit dans le signal capté et amplifié. Dans l'édition sur le SPL et la Distorsion, nous avons abordé la distorsion par clipping et les spécifications liées du microphone, telles que le SPL maximal et la plage dynamique. Toutes les spécifications abordées jusqu'à présent sont liées au niveau du signal.
Il est maintenant temps de tout rassembler et de voir comment ces éléments peuvent nous aider à choisir un microphone qui délivre un signal restant dans la Zone de Goldilocks du préamplificateur, ce qui entraînera moins de bruit et (espérons-le) pas de distorsion audible. Mais avant cela, nous devons comprendre certains concepts de base sur les signaux. Il y a beaucoup de choses à traiter ici ; si tu es impatient, peu curieux ou que tu crois encore que tu peux devenir ingénieur du son simplement en mémorisant des réglages vus sur Youtube, tu pourrais vouloir passer à l'édition suivante et revenir sur celle-ci plus tard pour mieux comprendre les raisons et le contexte historique.
LES FONDAMENTAUX DU SIGNAL ANALOGIQUE
Pour comprendre les spécifications des microphones et des préamplificateurs liées aux niveaux de signal, nous devons comprendre certains principes généraux des niveaux de signal analogiques, et la meilleure manière de le faire est de commencer par leurs limitations.
Comme nous l'avons appris dans les précédentes éditions, tout ce que le son traverse a des limites qui déterminent jusqu’où le niveau du signal peut aller, aussi bien dans les niveaux bas que dans les niveaux hauts.

Bruit
Le niveau le plus bas que le signal peut atteindre est déterminé par le bruit — qu’il s’agisse du bruit acoustique dans l’espace que le son traverse, du bruit brownien dans les diaphragmes de microphone, du bruit thermique dans les électroniques audio analogiques, ou du bruit de quantification dans les systèmes numériques. Le niveau du bruit détermine en fin de compte le niveau sonore le plus faible qui peut être entendu et/ou le niveau de signal le plus bas qui peut être capté ; à mesure que le niveau sonore ou le niveau du signal tombe trop loin vers le bruit, il devient inintelligible et finalement inaudible.
Paradoxalement, dans les systèmes audio numériques, nous ajoutons du bruit pour permettre au signal de rester intelligible et audible à faibles niveaux. Ce bruit s'appelle le dither (ou "hachage"), et le processus consistant à l'ajouter s'appelle dithering. Appliquer du dither à un signal numérique transforme la rugosité du bruit de quantification en un souffle beaucoup plus acceptable — il est généralement plus fort que le bruit de quantification, mais beaucoup moins intrusif. Il est également utilisé dans l’imagerie numérique pour améliorer la perception visuelle des images en basse résolution, mais le dither est un sujet pour une autre fois.
Distorsion
Le niveau le plus élevé que le signal peut atteindre est déterminé par le point où la forme d'onde du son ou du signal est altérée en raison d'une forme de distorsion connue sous le nom de clipping, où les crêtes de la forme d'onde sont aplaties comme si elles avaient été coupées avec des ciseaux — comme cela a été discuté dans l'édition précédente. Le clipping se produit dans les circuits audio analogiques (y compris ceux trouvés à l’intérieur des microphones à condensateur et des microphones actifs) lorsque le niveau de tension de crête du signal tente de dépasser la tension maximale utilisée pour alimenter le circuit. Il se produit dans les systèmes numériques lorsque la valeur numérique de crête du signal tente de dépasser 0dBFS, qui est le plus grand nombre que le système numérique peut représenter. Le clipping se produit également dans l’air lorsque le son dépasse 194 dB SPL, moment où la demi-cycle négatif de la forme d’onde raréfie les molécules d’air pour créer un vide complet — ce qui est la pression atmosphérique négative la plus élevée possible. [Cette forme de clipping est un problème pour ceux qui enregistrent des feux d'artifice, des lancements de fusées, des explosions et des orages, car le son est déjà "clippé" par l'air avant d'atteindre le microphone, et aucune modification de gain, de commutation de pad ou de changement de microphone ne pourra y remédier. Il est intéressant de noter que, parce qu’il est uniquement "clippé" lors des demi-cycles négatifs, il s’agit d’une forme asymétrique de clipping, ce qui introduit un équilibre différent des composants de distorsion harmonique par rapport au clipping symétrique et peut parfois sembler moins intrusif et, dans certains cas, plus musical — comme on peut l’entendre dans les amplificateurs de guitare électrique.] Dans tous les cas, si le niveau du signal dépasse trop loin dans le clipping, nous avons un problème.
Puisque notre objectif dans cette édition est de traiter des niveaux de signal, nous allons examiner comment les limitations du clipping et du bruit se manifestent dans les circuits audio tels que les préamplificateurs de microphones et les systèmes audio numériques, et comment cela influence nos choix de microphones. Mais d’abord, un rapide aperçu des trois types de niveaux de signal que nous rencontrons régulièrement dans l’ingénierie audio : Niveau Microphone, Niveau Ligne et Niveau Instrument.

Niveau Microphone (Mic Level)
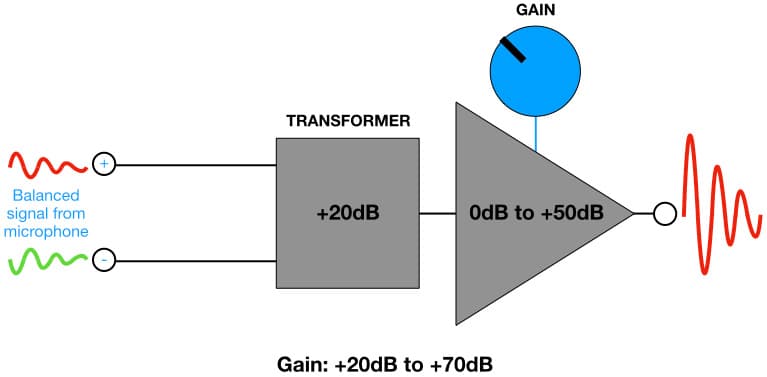
À moins que nous n’utilisions un microphone avec une sortie numérique (par exemple, AES42, USB ou MEMS), le signal présenté à la sortie de notre microphone est une très petite tension analogique, généralement mesurée en centièmes ou millièmes de volt. Lorsqu'il est converti en décibels, il se situe généralement entre -60dBu (0,000775 VRMS) et -20dBu (0,0775 VRMS). Ce signal est appelé Niveau Microphone, et il doit passer par un préamplificateur pour être porté à un niveau utile pour le traitement et/ou l’enregistrement (c'est-à-dire, Niveau Ligne).
Les signaux de Niveau Microphone utilisent des lignes équilibrées et des connecteurs XLR. Les patchbays dans certains studios d'enregistrement professionnels permettent de faire passer les lignes de microphone vers les entrées des préamplificateurs via des câbles Bantam TT symétriques et des prises, bien que la connexion des microphones se fasse de préférence avec des prises et des fiches XLR. La plupart des fabricants de connecteurs XLR conçoivent la broche 1 légèrement plus longue que les broches 2 et 3 sur leurs connecteurs XLR femelles (généralement utilisés comme entrées) afin de garantir que la broche 1 (terre) se connecte en premier, une fonctionnalité de sécurité utile. Le fabricant de microphones Røde fait exprès de rendre la broche 1 légèrement plus longue sur leurs sorties XLR de microphones (qui sont des XLR mâles) pour la même raison — une excellente idée qui malheureusement amène les personnes mal informées à penser qu’il s’agit d’un défaut de fabrication, car une broche est plus longue que les autres.
[Pour éviter les bruits de choc qui pourraient endommager les haut-parleurs de monitoring, les casques et l’audition, il est toujours conseillé de couper le monitoring lorsque vous patcher des microphones — surtout si vous utilisez l'alimentation fantôme, et encore plus si vous utilisez des connecteurs Bantam TT (plutôt que des XLR) parce que leur configuration anneau/pointe/manchon signifie que, pendant un court moment, vous pourriez fournir un signal d’entrée de +48V DC au microphone. Cela suffit à endommager les haut-parleurs passifs, les casques, l’audition humaine, et toute crédibilité que vous avez pu établir avec le client.]
Niveau Ligne (Line Level)
Le rôle du préamplificateur de microphone est d'amplifier le signal de Niveau Microphone à un niveau utile pour un traitement ultérieur, qui est généralement appelé Niveau Ligne.
La plupart des signaux de Niveau Ligne utilisent des lignes équilibrées avec des connecteurs XLR, des prises TRS ou les connexions Bantam TT que l'on retrouve dans les patchbays des studios d’enregistrement professionnels. Nous parlerons davantage des signaux de Niveau Ligne sous peu, car l’objectif final du préamplificateur est de porter le signal de Niveau Microphone à Niveau Ligne…
Niveau Instrument (Instrument Level)
Les guitares électriques, les claviers et autres instruments musicaux électroniques conçus pour les performances en direct fournissent leurs sorties sur des prises TS 6,35 mm (une pour mono, deux pour stéréo), destinées à être connectées à un amplificateur d'instrument. Les signaux qu'ils produisent sont souvent appelés Niveau Instrument ; ils sont plus élevés que le Niveau Microphone mais plus faibles que le Niveau Ligne, se situant généralement autour de -20dBu (0,0775 VRMS). Ces signaux sont trop faibles pour la plupart des entrées de Niveau Ligne mais trop forts pour les entrées de Niveau Microphone, et ils sont généralement asymétriques, ce qui signifie qu'ils conviennent pour les câbles courts entre l’instrument et son amplificateur, mais pas pour des câbles longs entre la scène et la table de mixage dans une application de sonorisation. Ils sont généralement connectés à une console de mixage ou à un préamplificateur de microphone via une boîte DI, qui réduit le signal relativement élevé mais asymétrique du Niveau Instrument à un signal de Niveau Microphone relativement faible avec une sortie symétrique, adaptée pour les longues distances et pour entrer dans un préamplificateur de microphone.
Le rôle du préamplificateur de microphone est d'amplifier le signal de Niveau Microphone à un niveau utile pour un traitement ultérieur, généralement appelé Niveau Ligne.
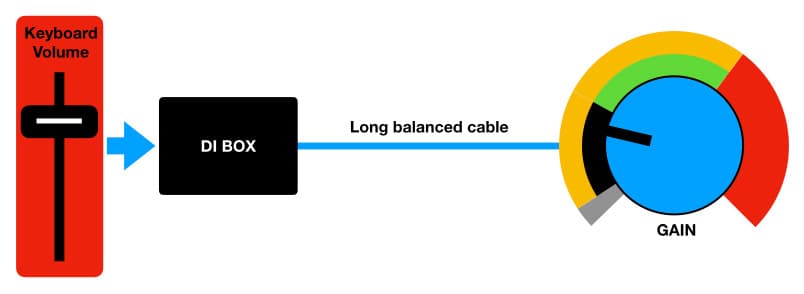
Certains claviers et modules montés en rack fournissent une sortie de Niveau Ligne symétrique sur une prise XLR ou Jack TRS, et cela devrait être utilisé chaque fois que possible pour se connecter à une entrée de Niveau Ligne.
Lorsque vous travaillez avec des signaux de Niveau Instrument dans des situations où l'instrument est proche du préamplificateur ou de la console de mixage, il est souvent nécessaire de jongler entre le niveau de sortie de l'instrument et le gain du préamplificateur pour trouver la connexion la plus silencieuse tout en évitant le clipping. Bien que l’utilisation d’une boîte DI sur une entrée de Niveau Microphone soit courante, dans certains cas, une meilleure qualité de signal peut être obtenue en branchant directement la sortie de l’instrument sur une entrée de Niveau Ligne avec un contrôle de Trim ou Gain ajustable.
Certaines interfaces, surtout celles conçues pour les musiciens s’enregistrant, disposent d'une entrée de Niveau Instrument avec une prise Jack TS 6,35 mm, spécialement conçue pour accepter les signaux de Niveau Instrument. Ce devrait être le premier choix pour cette application.
Dans tous les cas, il est important de trouver le bon équilibre entre le niveau de sortie de l'instrument et le gain du préamplificateur, de l'entrée de Niveau Instrument ou de Niveau Ligne, pour minimiser le bruit et éviter le clipping – soit en poussant le circuit de sortie de l'instrument dans la distorsion, soit en surchargeant l'entrée de la boîte DI, l'entrée de microphone, l'entrée d’instrument ou d’entrée de Niveau Ligne. Un bon point de départ consiste à régler le niveau de sortie de l’instrument à environ 70 % de sa valeur maximale, bien que le niveau réel du signal dépende du patch, de l’échantillon ou du clip utilisé.

[Concernant les patches, échantillons et clips utilisés lors des performances en direct, il est toujours bon de régler le niveau de sortie de chaque élément afin qu’il ait un niveau perçu similaire aux autres. Cela peut être fait à l’oreille ou avec un mètre SPL placé devant l’amplificateur de l’instrument, avec le niveau souhaité enregistré dans la mémoire utilisateur comme partie de chaque patch, échantillon ou clip. Cela simplifie la vie de l’artiste sur scène en minimisant le besoin d’ajuster le volume après chaque changement tout en essayant de jouer sa partie. Cela, à son tour, facilite le travail de l’ingénieur du son en direct, et les deux améliorations résultent en un concert de meilleure qualité.]
________________________________________
Qu'est-ce qu'un signal ?
Des livres entiers ont été écrits sur les signaux audio et les nombreuses façons dont nous pouvons les définir et les mesurer.
L'onde sinusoïdale est le signal le plus simple de tous (à part le silence absolu) et pourtant, il existe au moins quatre façons de définir son niveau, ou plus précisément, son amplitude. L'illustration ci-dessous montre un cycle d'une onde sinusoïdale (verte) avec une amplitude positive maximale de +1 et une amplitude négative maximale de -1. Elle montre également quatre différentes façons de mesurer et de définir l'amplitude de l'onde sinusoïdale, comme expliqué ci-dessous.

Crête-à-Crête (Peak-To-Peak)
Commençons par la droite de l'illustration avec Peak-To-Peak, qui est mesuré depuis le sommet de la demi-onde positive jusqu'au sommet de la demi-onde négative. Dans cet exemple, il a une valeur de deux (de +1 à -1), mais il est important de noter qu'à aucun moment la forme d'onde du signal n'atteint réellement la valeur de deux. En fait, dans cet exemple – qui utilise une forme d'onde symétrique où les demi-cycles positif et négatif sont des images miroir – l'amplitude la plus élevée qu'il atteindra est la moitié de la valeur Peak-To-Peak.
Les mesures Peak-To-Peak sont généralement indiquées par le suffixe « pp », par exemple « 2Vpp ». Les mesures Peak-To-Peak sont surtout utilisées pour déterminer ce qu'on appelle souvent l'amplitude du signal ; en d'autres termes, la différence entre l'amplitude positive maximale et l'amplitude négative maximale. L'onde sinusoïdale de l'illustration a une amplitude de deux volts. Ces mesures Peak-To-Peak sont utiles lorsqu'on conçoit des haut-parleurs et des alimentations pour des circuits audio, mais elles ne sont pas vraiment utiles dans notre cas.
Crête (Peak)
Comme on le voit dans l'illustration, la valeur Peak est mesurée depuis zéro jusqu'au sommet maximal positif ou négatif du signal. Dans l'illustration, il est mesuré au sommet positif maximal et a une valeur de +1. Comme l'onde sinusoïdale est une forme d'onde symétrique, on peut supposer que le pic négatif sera de la même valeur que le pic positif (à moins qu'il n'y ait un décalage continu), mais avec une polarité inversée. Contrairement à la valeur Peak-To-Peak, on peut voir que la forme d'onde du signal atteint réellement le niveau Peak – bien que de manière momentanée.
Les mesures Peak sont généralement indiquées par le suffixe « p », par exemple « 1Vp ». Les mesures Peak sont utiles pour déterminer à quel point un signal est proche du niveau maximal d'un appareil, c'est-à-dire le niveau maximal possible avant que la distorsion due au clipping ne se produise. Elles sont couramment utilisées dans les compteurs des équipements audio numériques, où 0dB est le niveau maximal avant le clipping. Les systèmes de mesure Peak considèrent les valeurs Peak des deux côtés de la forme d'onde (c'est-à-dire, les demi-cycles positif et négatif) pour s'assurer que rien ne dépasse à cause d'une forme d'onde non symétrique ou d'un décalage continu.
Moyenne et RMS
Le problème avec les mesures Peak est que de nombreux signaux audio (y compris l'onde sinusoïdale dans l'illustration) ne sont à leur niveau Peak que pendant une brève portion de leur durée. Une mesure Peak fournit une bonne indication de l'amplitude la plus élevée atteinte par le signal, ce qui est utile pour prévenir la distorsion due au clipping, mais elle ne nous dit pas grand-chose d'autre sur le signal – par exemple, à quel point il sera perçu comme fort par rapport à d'autres signaux ayant la même valeur Peak, ce que l'on appellerait son loudness/sonie relatif perçu. Pour des valeurs qui nous permettent de comparer le loudness/sonie relatif de différents signaux, les mesures Moyenne et RMS sont plus utiles que les mesures Peak.
La valeur Moyenne pour une onde sinusoïdale se calcule de la manière suivante :
Moyenne = 0,637 x Pic
Les mesures Moyenne sont généralement indiquées par le suffixe « av », par exemple « 0,637Vav ». L'onde sinusoïdale dans l'illustration ayant une amplitude Peak de 1V, son amplitude Moyenne est :
0,637 x 1 = 0,637Vav
RMS est l'acronyme de Root Mean Square (moyenne quadratique), ce qui décrit le processus mathématique utilisé pour en déterminer la valeur. Les ingénieurs électriques l'appelaient autrefois la heating value, ce qui donne un indice sur ses origines. La valeur RMS pour une onde sinusoïdale se calcule de la manière suivante :
RMS = 0,7071 x Pic
Les mesures RMS sont généralement indiquées par le suffixe « rms », par exemple « 0,7071Vrms ». L'onde sinusoïdale dans l'illustration ayant une amplitude Peak de 1V, son amplitude RMS est :
0,7071 x 1 = 0,7071Vrms
Les mesures données en dBu, comme indiqué précédemment dans cet article, sont basées sur les valeurs RMS où 0dBu = 0,775Vrms. Une valeur de -20dBu signifie que le signal est 20dB plus bas que 0dBu, ce qui signifie qu'il est 20dB plus bas que 0,775Vrms, soit 0,0775Vrms. Comme astuce rapide pour les dB, il est bon de savoir que 20dB représente un facteur de 10, donc -20dB signifie ÷10, et +20dB signifie x10. Ainsi, -20dBu est 1/10e de 0dBu, ce qui est 1/10e de 0,775Vrms.
Notez que les formules pour les valeurs Moyenne et RMS ci-dessus ne s'appliquent qu'aux ondes sinusoïdales. Les formules de calcul des valeurs Moyenne et RMS pour d'autres formes d'ondes deviennent de plus en plus complexes à mesure que la forme d'onde devient complexe.
Pour les applications audio, les valeurs Moyenne et RMS donnent toutes deux une meilleure indication du loudness/sonie relatif perçu d'un signal. Cependant, aucune des deux n'est aussi efficace que le système de mesure LUFS lorsqu'il s'agit de comparer et d'ajuster le loudness/sonie relatif perçu de différents signaux. Tu as probablement entendu parler des LUFS (Loudness Units Full Scale) en référence au mastering des mixes pour les services de streaming. Le loudness/sonie perçu est généralement un sujet de mastering, donc en quoi cela concerne-t-il le choix des microphones et la configuration du gain ? Continue à lire...
Microphones, Gain et loudness/sonie?
Tous les appareils audio numériques possèdent une mesure Peak pour nous aider à empêcher les niveaux de signal de dépasser le niveau maximal (0dBFS) et de provoquer de la distorsion. Certaines DAWs (stations de travail audio numériques) offrent également des mesures RMS et/ou Moyenne qui sont généralement superposées à la mesure Peak, et il existe des plug-ins et des applications qui proposent de nombreuses options de mesure.
Nous ne pouvons pas utiliser les niveaux Peak pour comparer le loudness/sonie perçu de différents signaux audio, car le système auditif humain ne prête pas beaucoup d'attention aux pics de courte durée comme ceux trouvés dans un son percussif. Au contraire, il évalue la loudness/sonie d'un son en utilisant un système de moyenne complexe qui nécessite des capacités de traitement de signal importantes pour l’émuler.

C'est une excellente illustration de la façon dont la loudness/sonie perçue diffère des niveaux de Pic dans les signaux audio !
Lorsque nous regardons ces deux formes d'onde, bien que la voix et le kick aient les mêmes niveaux de Pic (les points les plus élevés atteints par chaque forme d'onde), elles n'ont pas la même loudness/sonie perçue. La raison en est que la loudness/sonie perçue est influencée non seulement par le niveau de Pic, mais aussi par la durée, le spectre de fréquence et les transitoires présents dans le son.
• Piste vocale : Les voix ont généralement un spectre de fréquences plus large qui correspond à la plage de sensibilité de l'audition humaine. Nos oreilles sont plus sensibles aux fréquences moyennes (où se trouvent la plupart des voix) qu'aux sons de basse fréquence, ce qui rend la voix perçue comme plus forte, même si son niveau de Pic est plus bas que celui d'un kick.
• Kick : Bien que le kick puisse avoir un niveau de Pic plus élevé que la voix, une grande partie de son énergie est concentrée dans des pics de courte durée (transitoires) et des fréquences basses, où l'audition humaine est moins sensible. Cela fait que le kick semble plus faible en termes de loudness/sonie perçue, même si son niveau de Pic est plus élevé.
Ainsi, dans la deuxième illustration où le niveau de la voix a été réduit pour correspondre à la loudness/sonie perçue du kick, le niveau de Pic du kick est beaucoup plus élevé, mais la loudness/sonie perçue est similaire. Cela nous aide à comprendre pourquoi différents instruments ou sons dans un mix peuvent ne pas toujours correspondre à leurs niveaux de Pic en ce qui concerne la façon dont ils sont perçus comme forts ou faibles.
Cette différence est également la raison pour laquelle la mesure en LUFS (Loudness Units relative to Full Scale) est une méthode plus précise pour mesurer la loudness/sonie perçue, car elle prend en compte la sensibilité aux fréquences et la pesée dans le temps pour mieux correspondre à la façon dont nous percevons le son.

Facteur de crête (Crest Factor)
En termes audio, le Crest Factor (facteur de crête) d'un signal décrit la différence entre le niveau Peak (crête) et le niveau Moyenne d'un signal, et est généralement exprimé en décibels. Les sons percussifs (comme la grosse caisse dans les exemples ci-dessus) ont un niveau Peak élevé, mais un niveau Moyenne faible, ce qui leur donne un Crest Factor élevé, mais une faible loudness/sonie perçue. En comparaison, les sons non percussifs (comme la voix dans les exemples ci-dessus) ont un Crest Factor beaucoup plus faible, ce qui permet un niveau Moyenne plus élevé et donc une loudness/sonie perçue plus forte.
Un signal avec un Crest Factor élevé aura besoin de plus d'Headroom (voir ci-dessous) qu'un signal avec le même niveau Moyenne mais un Crest Factor plus faible.
Lors du mastering audio pour se conformer aux exigences de plage dynamique limitée des services de streaming, l'un des objectifs est de réduire le Crest Factor du signal afin que le niveau Peak soit plus bas. Cela permet d'augmenter le niveau Moyenne – ce qui augmente ainsi la loudness/sonie perçue.
VU & LUFS
Le problème de l'indication de la loudness/sonie perçue nous a donné le VU meter (voltmètre), dans les années 1930, comme moyen de maintenir une loudness/sonie constante dans les applications de diffusion, où le matériel programmatique passait régulièrement d'une voix d'annonceur à une autre ou à différents morceaux de musique. « VU » signifie Volume Unit (unité de volume), où volume fait référence à la loudness/sonie perçue, et non à un espace cubique. Le VU meter utilise des mesures ballistiques relativement lentes (c'est-à-dire la vitesse à laquelle l'aiguille peut se déplacer) avec des temps d'attaque et de relâchement d'environ 300 ms (0,3 s), ce qui lui confère un effet de moyennage. L'aiguille bouge trop lentement pour suivre les pics transitoires de la grosse caisse montrée précédemment, ce qui provoque une perception tronquée de ces niveaux de loudness/sonie perçues. L'idée de base est (ou était) que si tous les signaux envoyés à l'antenne ont à peu près le même niveau sur le VU meter, alors ils devraient avoir une loudness/sonie perçue à peu près équivalente. Il ne devrait donc y avoir aucune surprise soudaine lors du passage entre les voix des annonceurs et/ou la musique populaire de l'époque. Le VU meter fonctionnait assez bien pour cette application, mais ses limites sont devenues évidentes avec l'introduction de l'enregistrement multitrack et de la prise de son rapprochée (close miking) des instruments de musique individuels, en particulier lors du travail avec des sons percussifs/ pincés ayant des transitoires rapides et des décays courts, comme la grosse caisse montrée plus tôt.
Les systèmes de diffusion numérique contemporains sont confrontés au même problème que les premiers diffuseurs analogiques, sauf qu'ils doivent passer d'un type de source sonore à l'autre (narration/dialogue, différents genres de musique et sons, films, etc.) à la demande, et contrairement aux premiers diffuseurs, il n'y a pas d'ingénieur qui surveille ce qui est "diffusé" en temps réel pour effectuer des ajustements lorsque les niveaux sont trop forts ou trop faibles. Cela a conduit à l'affinement du système de mesure LUFS, tel que décrit dans la norme EBU R128 et basé sur les recommandations de l'ITU BS1770. C'est un indicateur bien plus précis de la loudness/sonie perçue que le VU meter ; si deux signaux ont la même valeur LUFS intégrée (c'est-à-dire la moyenne sur la durée du signal), ils auront probablement la même loudness/sonie perçue en général. Les services de streaming ont adopté des niveaux LUFS intégrés spécifiques pour maintenir une loudness/sonie constante lors de la lecture – c'est pourquoi vous pouvez généralement passer d'une vidéo à l'autre sur YouTube ou entre plusieurs morceaux de musique sur Spotify sans subir de changements importants dans la loudness/sonie perçue. La mesure LUFS intégrée peut fournir des indications très précises de la loudness/sonie perçue, mais quel rapport cela a-t-il avec le choix des microphones et le réglage du gain ? Continuez à lire…

Niveau de Fonctionnement Nominal (Nominal Operating Level - NOL)
Les VU meters sont toujours populaires sur les appareils audio analogiques, et tous les appareils audio analogiques partagent les limitations de bruit et de distorsion mentionnées précédemment. Le bruit est un problème lorsque le niveau du signal devient trop faible, et la distorsion est un problème lorsque le niveau du signal devient trop élevé. Parce que les signaux audio peuvent varier considérablement entre leurs niveaux de Peak et leurs niveaux perçus (qu'ils soient mesurés en Moyenne, RMS ou LUFS), les équipements audio analogiques professionnels suivent un concept connu sous le nom de Niveau de Fonctionnement Nominal (NOL) – un niveau de signal recommandé qui est suffisamment élevé pour que le niveau perçu soit au-dessus du bruit, mais (idéalement) suffisamment bas pour empêcher que le niveau de Peak ne provoque de distorsion due au clipping. Le NOL est représenté par 0dB sur un VU meter et est donc appelé 0dBVU. Les signaux qui se trouvent au niveau du NOL sont également appelés Line Level, comme mentionné précédemment.
Dans les équipements audio analogiques professionnels, le NOL de 0dBVU est normalisé à un niveau de signal de +4dBu, ce qui est équivalent à une tension de 1.228VRMS lorsqu'il est mesuré à l'aide d'une onde sinusoïdale de 1 kHz comme signal. Autrement dit, si une onde sinusoïdale de 1 kHz est passée à travers l'équipement et que son niveau est ajusté pour lire 0dBVU sur le VU meter, elle aura une tension de 1.228VRMS. Cette norme permet à tous les éléments du studio d'enregistrement analogique d'être calibrés sur le même NOL de +4dBu, de sorte que 0dBVU à la sortie de la console de mixage donne 0dBVU à l'entrée des enregistreurs à bande et des processeurs d'effets, et vice versa. Lorsque tout est calibré sur le même NOL, tous les appareils individuels du système audio analogique deviennent essentiellement un seul et grand appareil intégré. Si nous réglons correctement le niveau au préamplificateur, il devrait être correct pour le reste du système – du moins jusqu'à ce que nous commencions à pousser les faders loin de leurs positions 0dB (ou Unity/Unité), à appliquer de l'égalisation, à utiliser de la compression et à faire d'autres actions qui affectent le niveau du signal.
Si nous connaissons le NOL d'un appareil audio analogique, ainsi que son Niveau Maximum (le niveau où la distorsion due au clipping se produit) et son Noise Floor (le niveau de son bruit), nous pouvons calculer ses spécifications pour la Plage Dynamique, le S/N Ratio et le Headroom, comme indiqué ci-dessous.

Le Niveau de Fonctionnement Nominal (NOL) est un concept essentiel dans les équipements audio, garantissant le meilleur équilibre entre la force du signal, le bruit et la distorsion. Il est généralement représenté par 0dBVU sur un mètre VU, qui, pour les équipements audio analogiques professionnels, est standardisé à un niveau de signal de +4dBu. Le +4dBu correspond à une tension de 1.228VRMS lorsqu'il est mesuré avec une onde sinusoïdale de 1 kHz.
Ce NOL standardisé garantit que les appareils audio dans une chaîne d'enregistrement ou de diffusion sont calibrés à un même niveau de signal, ce qui aide à maintenir des niveaux audio cohérents à travers le système. Par exemple, un signal réglé pour afficher 0dBVU sur le mètre VU correspondra à +4dBu lorsqu'il passe par un équipement analogique professionnel, fournissant une référence pour tous les appareils connectés à s'aligner.
Application Pratique
Lorsque tous les équipements sont calibrés au même NOL (par exemple, +4dBu), il devient plus facile de travailler avec divers appareils dans une configuration de studio analogique, comme les consoles de mixage, les enregistreurs à bande et les processeurs d'effets. Si le niveau est correctement réglé à l'étape du préamplificateur, il devrait se propager de manière cohérente dans tout le système, sauf si d'autres facteurs comme l'EQ, la compression ou les ajustements de fader modifient le niveau du signal.
Cependant, pour atteindre le bon équilibre et une performance optimale, il est nécessaire de prendre en compte la Plage Dynamique, le Rapport Signal/Bruit (S/N) et la Marge de Sécurité de chaque appareil dans la chaîne audio. Ces facteurs contribuent à maintenir un signal suffisamment fort pour éviter la distorsion (clipping), tout en restant suffisamment au-dessus du niveau de bruit pour garantir une bonne qualité sonore.
Plage Dynamique, Rapport Signal/Bruit et Marge de Sécurité
• Plage Dynamique : La différence entre les parties les plus silencieuses et les plus fortes du signal audio. Dans un contexte professionnel, cette plage doit être suffisamment large pour éviter la distorsion tout en permettant aux sons faibles de rester audibles et clairs.
• Rapport Signal/Bruit (S/N) : Le rapport entre le niveau du signal et le niveau de bruit de fond. Un rapport S/N plus élevé signifie que le signal est beaucoup plus clair par rapport au bruit de fond, ce qui est crucial dans les équipements audio professionnels pour éviter le souffle ou les ronflements qui altéreraient la qualité sonore globale.
• Marge de Sécurité : L'espace entre le niveau moyen du signal et le niveau maximum avant que la distorsion ou le clipping n'intervienne. Cela est essentiel pour éviter la distorsion, en particulier lorsqu'il y a des pics inattendus dans le signal audio, comme dans les sons percussifs ou les pics soudains de volume.
Relation avec les Microphones
Dans les chapitres précédents, nous avons discuté de la manière dont les microphones interagissent avec ces concepts, en particulier comment leur niveau de sortie doit être amplifié au Niveau Ligne par les préamplificateurs et comment régler correctement le gain aide à maintenir le bon niveau de signal à travers le système. Un bon réglage du gain garantit que le signal du microphone reste au-dessus du niveau de bruit, mais ne dépasse pas le niveau maximum du système, où la distorsion pourrait se produire.
Impact sur le Chemin du Signal
En respectant le Niveau de Fonctionnement Nominal (NOL) de +4dBu, vous vous assurez que le signal audio conserve sa clarté, sa cohérence et sa qualité tout au long de son parcours, du microphone à la sortie finale. Cependant, il est important de prêter attention au Niveau Maximum de l'équipement, où commence la distorsion, ainsi qu'au Niveau de Bruit, afin de prévenir la dégradation de la qualité sonore. Comprendre les spécifications de Plage Dynamique, de Rapport Signal/Bruit et de Marge de Sécurité de chaque appareil audio vous aidera à prendre de meilleures décisions lors du routage des signaux et des réglages du gain pour obtenir une performance optimale.
Rapport Signal/Bruit (S/N Ratio)
Dans les précédentes sections, nous avons vu que la spécification du Rapport Signal/Bruit (S/N Ratio) du microphone est définie comme la différence entre 94dB SPL et le niveau de bruit équivalent du microphone ou le bruit propre. Un SPL de 94dB au niveau du diaphragme était utilisé comme point de référence pour représenter le signal. Dans les équipements audio analogiques professionnels, le point de référence est le Niveau de Fonctionnement Nominal (NOL) de l'appareil, et le Rapport Signal/Bruit est défini comme la différence entre le NOL et le niveau de bruit de l'appareil. Il est spécifié en dB, et une valeur plus élevée signifie un meilleur rapport S/N – c'est-à-dire un bruit plus faible. Comme montré dans l'illustration précédente :
S/N Ratio = Niveau de Fonctionnement Nominal - Niveau de Bruit
Headroom (Marge de Sécurité/ plafond)
La spécification de la Marge de Sécurité décrit la différence entre le NOL d'un appareil et son Niveau Maximum. En d'autres termes, cela montre jusqu'à quel point le signal peut dépasser le NOL avant d'atteindre le clipping. Comme illustré précédemment :
Headroom = Niveau Maximum - Niveau de Fonctionnement Nominal
La plupart des équipements audio analogiques professionnels offrent au moins 20dB de Marge de Sécurité, et tout ce qui est inférieur est généralement considéré comme insuffisant. C’est une information utile que nous reviendrons voir plus tard lorsque nous examinerons comment les équipements numériques s’intègrent dans le monde analogique du son. Pour un NOL donné, plus la Marge de Sécurité est grande, mieux c’est. Les mesureurs de crête (Peak meters) présents sur les appareils audio numériques sont parfois appelés "mesureurs de Marge de Sécurité" car ils montrent combien de Marge de Sécurité reste entre le pic du signal et le niveau maximum de l'appareil.
La Marge de Sécurité est rarement, voire jamais, mentionnée pour les microphones, mais elle peut être calculée à partir de la spécification du SPL Maximum du microphone, moins 94dB SPL. En essence, nous pouvons utiliser 94dB SPL comme le Niveau de Fonctionnement Nominal du microphone, tout comme lors du calcul du Rapport Signal/Bruit du microphone.
Plage Dynamique
Dans l'édition précédente, nous avons vu que la spécification de la Plage Dynamique du microphone décrivait la différence entre le niveau de son bruit et la spécification de son SPL Maximum (le point où le clipping se produit). La même logique s'applique à la Plage Dynamique des équipements audio analogiques professionnels – elle est définie comme la différence entre le Niveau de Bruit de l'appareil et son Niveau Maximum. Elle est spécifiée en dB, et une valeur plus grande signifie que l'appareil possède une Plage Dynamique plus large, ce qui peut aussi signifier un meilleur Rapport S/N, plus de Marge de Sécurité, ou les deux. Comme montré dans l'illustration précédente :
Plage Dynamique = Niveau Maximum - Niveau de Bruit
Et aussi comme indiqué dans l'illustration :
Plage Dynamique = Marge de Sécurité + Rapport S/N
Niveau d'Alignement (Alignment Level)
Les choses sont différentes dans le monde numérique. Le bruit inhérent aux systèmes numériques est tellement faible comparé au bruit d'un système analogique (surtout lorsqu'on utilise des enregistreurs à bande analogiques) que la nécessité d'un NOL n'est pas immédiatement évidente. La principale exigence est de s'assurer que le niveau de crête du signal ne dépasse pas le niveau maximum du système numérique, qui est représenté par 0dBFS sur le mesureur numérique du système. Le "FS" dans "dBFS" signifie Full Scale, où 0dBFS représente le Niveau Maximum (ou niveau de clipping) et le dépasser entraîne de la distorsion. À l'exception de 0dBFS, tous les autres niveaux dBFS sont donnés en nombres négatifs, représentant la distance entre le niveau de crête du signal et le niveau maximum. Par exemple, un niveau de -12dBFS signifie que le niveau de crête du signal est à 12dB en dessous du niveau où se produit le clipping. Cela semble simple, mais il y a plus à comprendre…
À un certain moment, nous devons introduire un signal analogique dans le système numérique depuis nos microphones et autres sources sonores analogiques, et à un autre moment, nous devons sortir un signal analogique du système numérique pour le connecter à des casques, des moniteurs ou des processeurs analogiques externes. Cela signifie que le système numérique doit finalement avoir des circuits d'entrée et/ou de sortie analogiques (c'est-à-dire des convertisseurs analogique-numérique et numérique-analogique), et pour les parties analogiques de ces circuits, toutes les spécifications analogiques mentionnées précédemment restent valables. De plus, si notre équipement numérique professionnel doit être intégré avec notre équipement analogique professionnel (par exemple, utiliser un DAW avec une console de mixage analogique ou un processeur, ou utiliser des plug-ins qui modélisent des processeurs analogiques vintage), il doit avoir un équivalent numérique du NOL de l'équipement analogique professionnel – un niveau de référence qui se conforme à +4dBu tout en permettant suffisamment de marge pour le signal provenant des dispositifs analogiques. Cela est généralement appelé un Niveau d'Alignement, et c'est l'équivalent numérique du NOL du système analogique.
0dBFS ? 0dBVU
La plupart des premiers enregistreurs numériques multipistes (par exemple, Sony 3348, Mitsubishi X850) conçus pour être utilisés dans des studios multipistes analogiques avaient des niveaux d'alignement compris entre -19dBFS et -24dBFS pour +4dBu, ce qui permettait de maintenir le NOL du studio analogique et de les installer directement à la place d'un enregistreur multipistes analogique. Comme avantage supplémentaire, ils offraient plus de Marge de Sécurité que les enregistreurs à bande analogiques qu'ils remplaçaient, lesquels n'offraient que rarement plus de 12dB au-dessus du NOL (0dBVU) avant d'entrer en saturation de la bande – l'équivalent magnétique du clipping, qui peut être euphonique à petites doses.
Un problème intéressant avec les premiers enregistreurs numériques multipistes était que, bien que leurs entrées et sorties se conforment au concept de NOL +4dBu du studio analogique, leur mesureur utilisait l'échelle dBFS où 0dBFS représente le Niveau Maximum – ce qui n'est pas le même que le NOL représenté par 0dBVU.

Cela a créé de la confusion chez les ingénieurs du son expérimentés qui avaient affiné leurs compétences dans un monde où les niveaux de signal devaient être maintenus autour de 0dB sur un système de métrologie conçu pour afficher une forme de loudness/sonie perçue relative (le mètre VU), et où il y avait toujours de la Marge de Sécurité pour aller au-dessus de 0dB. Comment transférer leurs compétences de réglage de niveau dans un système de métrologie numérique où 0dB est le niveau maximum et ne peut pas être dépassé ?
La fidélité à la vieille règle analogique de garder les niveaux de signal aussi proches que possible de 0dB, combinée à la nouvelle règle numérique de ne pas laisser le signal dépasser 0dB, a mis en évidence les malentendus entre 0dBVU et 0dBFS. Dans de nombreux studios hybrides des premiers temps (consoles analogiques avec enregistreurs multipistes numériques), les sorties des bus de la console étaient souvent poussées 12dB ou plus au-dessus du NOL de 0dBVU pour rapprocher les niveaux de signal de 0dBFS sur les mètres des enregistreurs numériques, comme les ingénieurs pensaient qu'ils devaient faire en maintenant les niveaux proches de 0dB.
Gritty-Sweet 16
Les préoccupations concernant les tailles de mots en 16 bits et le traitement étaient souvent écartées par l'idée qu'il n'était pas nécessaire d'aller au-delà de 16 bits, car c'était le meilleur que le CD puisse offrir – une justification mathématiquement mal informée qui allait à l'encontre d'une des vérités les plus anciennes du monde de l'audio : que les équipements de capture et de production doivent toujours avoir de meilleures spécifications que le support de diffusion, car chaque étape du processus de production réduit la qualité, particulièrement en termes de bruit. Dans le monde analogique, le bruit accumulé des processus d'enregistrement, de production et de mastering (bruit de la salle, bruit thermique, souffle de la bande, bruit de surface du lacquer et du stamper) ne posait pas de problème tant qu'il restait suffisamment bas par rapport au bruit des supports de diffusion, c'est-à-dire le bruit de surface du vinyle pressé ou le souffle de la cassette. La même chose est vraie dans le monde numérique, sauf que le bruit des systèmes numériques (bruit thermique des circuits d'entrée et de sortie analogiques, bruit de quantification lors de la conversion et du traitement, bruit de dithering ajouté pour dé-corréler et masquer le bruit de quantification) est bien plus faible dès le départ, ce qui en fait rarement un problème, même après un traitement considérable.
Pour mieux comprendre cela, certains des premiers studios à adopter des enregistreurs numériques multipistes ont rapidement découvert que le bruit de fond de leurs espaces d'enregistrement et le bruit de leurs consoles (qui était auparavant masqué par le souffle de la bande analogique) étaient désormais audibles dans leurs enregistrements et pouvaient être entendus s'accumulant avec chaque nouvelle piste. C'était un problème intéressant – retirer le bruit de la bande analogique a mis en évidence ce qui était caché.
De même, lors de l'utilisation des premiers systèmes multipistes entièrement numériques qui utilisaient la technologie 16 bits, l'erreur de quantification accumulée et sa "rugosité" associée sont devenues évidentes en l'absence de tout bruit analogique (par exemple, bruit thermique de la console de mixage analogique) pour la cacher ou la dé- corréler via un dithering accidentel – ce qui explique pourquoi cette "rugosité" ne posait pas de problème dans les premiers studios hybrides utilisant des consoles de mixage analogiques avec des enregistreurs multipistes numériques 16 bits. [Cela explique aussi en partie le phénomène des "mixeurs de sommation", mais c'est une autre histoire…]
Qu'est-ce que tout cela a à voir avec le choix des microphones et le réglage du gain ? Cela met en lumière l'histoire de certains malentendus tenaces concernant les niveaux de signal dans les systèmes audio numériques, et il est crucial de bien régler les niveaux de signal dans les systèmes audio numériques lors du choix des microphones et du réglage du gain – comme nous allons le voir sous peu.
RP-155
Au début des années 1990, la SMPTE (Society of Motion Picture and Television Engineers) a proposé la norme RP-155 qui recommande un Niveau d'Alignement de -20dBFS. Selon RP-155, si une onde sinusoïdale de 1kHz à +4dBu entre dans l'entrée ligne analogique de l'appareil numérique, son mètre devrait afficher -20dBFS, et si cette même onde sinusoïdale à -20dBFS sort de la sortie ligne analogique de l'appareil numérique, elle devrait mesurer +4dBu. RP-155 donne au système numérique 20dB de Marge de Sécurité, ce qui est suffisant pour la plupart des applications musicales et de dialogue.
Comment les spécifications analogiques mentionnées précédemment s'intègrent-elles dans un système de mesure numérique aligné selon RP-155 ? Nous savons déjà que le Niveau Maximum du système numérique (0dBFS) et son Niveau d'Alignement (-20dBFS, équivalent au NOL dans le monde analogique), ce qui signifie que nous pouvons calculer sa Marge de Sécurité (20dB). Pour calculer le Rapport Signal/Bruit d'un système numérique, nous devons connaître sa Plage Dynamique, que nous pouvons calculer si nous connaissons sa taille de mot (bitword)…
La forme la plus courante de l'audio numérique, utilisée dans les CD et les fichiers wav, est appelée Linear PCM (ou LPCM ou simplement PCM). Calculer la Plage Dynamique pour un système Linear PCM est simple : elle est de 6.0206dB par bit, bien que cela soit couramment arrondi à une valeur de référence de 6dB par bit. Nous utiliserons 6dB par bit pour cet exercice. Un fichier wav de 24 bits offre une Plage Dynamique de 24 x 6 = 144dB, ce qui dépasse facilement ce que les circuits analogiques pratiques peuvent offrir. Si la Plage Dynamique est de 144dB et que le niveau maximum est 0dBFS, le niveau minimum sera -144dBFS. En tenant compte de quelques dB dus au bruit d'erreur de quantification et au dithering, cela donne un Niveau de Bruit qui se situe toujours quelque part en dessous de -140dBFS.
L'illustration ci-dessous montre comment les spécifications analogiques mentionnées précédemment s'intègrent dans un système numérique 24 bits et un système numérique 16 bits, tous deux alignés selon RP-155 afin que -20dBFS = +4dBu.
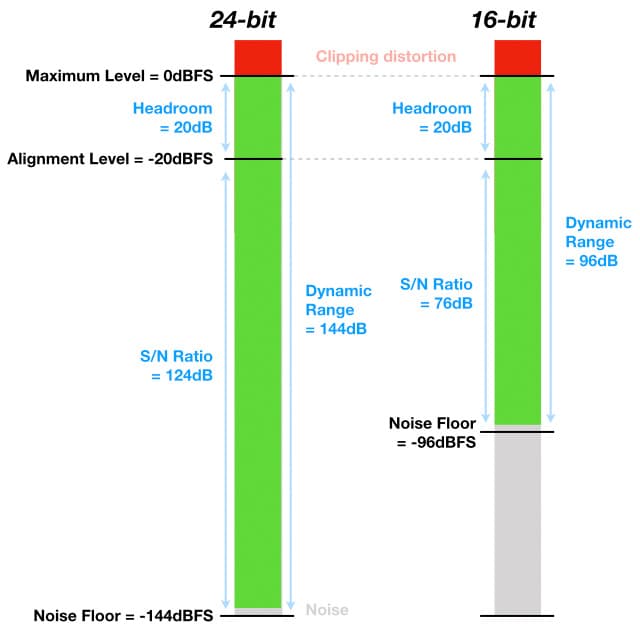
Connaître ces informations permet d'optimiser les systèmes qui combinent équipements analogiques et numériques. Par exemple, utiliser le Niveau d'Alignement recommandé par RP-155 de -20dBFS pour un enregistreur numérique a du sens si le préamplificateur du microphone qui l'alimente dispose également de 20dB de Marge de Sécurité – les deux appareils ont le même Niveau Maximum, les deux entreront en clipping en même temps et aucun des deux ne gaspille sa capacité de Marge de Sécurité.
Si le préamplificateur du microphone était un appareil plus coûteux avec 24dB de Marge de Sécurité, il serait alors logique de régler le Niveau d'Alignement de l'enregistreur numérique à -24dBFS, sinon nous gaspillons les capacités de Marge de Sécurité du préamplificateur, car l'enregistreur numérique entrera en clipping avant le préamplificateur.

Marge de Sécurité (Safety Margin)
Alternativement, nous pourrions utiliser la Marge de Sécurité supplémentaire du préamplificateur pour créer une "marge de sécurité", de manière similaire à celle utilisée dans les bandes analogiques qui avaient moins de Marge de Sécurité que le préamplificateur ou la console qui les alimentait, mais qui n'entraient pas instantanément en clipping lorsqu'elles étaient poussées au-delà de leur Marge de Sécurité. Au lieu de cela, elles entraient en saturation de la bande, ce qui, entre autres, offrait un effet de compression léger qui laissait une certaine marge d'erreur avant que le signal devienne inutilisable.
Aligner le préamplificateur et l'enregistreur numérique dans cet exemple de sorte que +4dBu = -20dBFS signifie que le préamplificateur décrit ci-dessus dispose de 4dB de Marge de Sécurité supplémentaire au-dessus du 0dBFS du système numérique. En insérant un compresseur à « knee » raide entre la sortie du préamplificateur et l'entrée de l'enregistreur numérique avec un seuil de +20dBu (-4dBFS sur le système numérique), un ratio de 2:1 et des temps d'attaque et de relâchement très rapides, les derniers 8dB de la Marge de Sécurité du préamplificateur seront compressés dans les derniers 4dB de la Marge de Sécurité du système numérique. Le réglage des niveaux afin d'empêcher les pics de dépasser -4dBFS signifie qu'il y a une marge de sécurité de 8dB dans le préamplificateur qui a été compressée dans les derniers 4dB du système numérique, au cas où un pic de niveau passerait au-delà de -4dBFS. Dans cet exemple, le compresseur aurait évidemment besoin de la même Marge de Sécurité ou d'une plus grande Marge de Sécurité que le préamplificateur, et l'objectif serait de régler le gain pour éviter que les niveaux de crête n'atteignent normalement -4dBFS, de manière à ce que la marge de sécurité soit véritablement une "marge de sécurité". Ce concept peut être appliqué de manière plus subtile, comme nous allons le voir sous peu…

Niveau Maitrisés et Normalisés
La recommandation RP-155 a été formulée il y a plusieurs années ; le fait qu'elle reste pertinente témoigne de la compréhension traditionnelle de l'audio analogique, qui reconnaît qu'un signal audio n'est pas uniquement défini par son niveau de crête.
À peu près à la même époque où la recommandation RP-155 a été faite, l'EBU (Union Européenne de Radiodiffusion) a recommandé un Niveau d'Alignement de -18dBFS. Il est 2dB plus élevé que celui de RP-155, offrant ainsi 2dB de marge de sécurité en moins. Cela ne pose pas de problème majeur pour les radiodiffuseurs travaillant avec des voix parlées et des matériaux musicaux déjà maîtrisés. Cependant, cela frôle le seuil d'insuffisance pour travailler avec des instruments de musique enregistrés de près (close-miking), mais en pratique, régler le gain d'un signal musical capté de près pour que son niveau de crête moyen oscille autour de -18dBFS ou -20dBFS tout au long de la performance donne un résultat très similaire – surtout lorsque l'on travaille avec des sources sonores qui peuvent s'éloigner ou se rapprocher du micro pendant l'enregistrement.
Des travaux complémentaires menés par CBS (Columbia Broadcasting System), l'ITU (Union Internationale des Télécommunications) et d'autres ont suggéré des lignes directrices qui intègrent des éléments précieux des systèmes de mesure analogiques bien établis (comme les VU et PPM) dans les systèmes de mesure numériques. Pourquoi cela ? Parce qu'il y a bien plus dans un signal audio que son simple niveau de crête – comme nous le verrons dans la suite…